
背景
GOSSIP 是一种分布式系统中常用的协议,用于在节点之间传播信息,维护集群拓扑结构。通过 GOSSIP 协议,Redis Cluster 中的每个节点都与其他节点进行通信,并共享集群的状态信息,最终达到所有节点拥有相同的集群状态。
在 Redis Cluster 中,Slot 和 Node 是两个关键概念,用于实现数据分片和高可用性。它们分别代表以下内容:
- Slot(槽):Slot 是 Redis Cluster 分割数据的基本单位。数据被分成 16384 个槽,每个槽都可以存储一个键值对。槽的范围是从 0 到 16383。Redis Cluster 使用哈希函数将键映射到特定的槽,从而决定了数据在集群中的分布。
- Node(节点):Node 是 Redis Cluster 中的一个实例或服务节点。每个节点都是一个独立的 Redis 服务,并负责管理一部分槽的数据。每个节点可以担任主节点或从节点的角色。主节点负责处理客户端请求和写入操作,而从节点复制主节点的数据,并处理读取请求。
区分两个概念是为了实现水平扩展,当集群需要扩展时,可以添加新的节点并将一部分槽分配给它。
GOSSIP 协议的核心作用也跟这两个概念强相关,通过 GOSSIP:
- 构建和维护了集群的槽分配图,包括槽的分配情况(即每个节点负责哪些槽),使得每个节点能够了解其他节点负责的槽信息。
- 构建和维护了集群的拓扑视图,包括节点的 ID、IP 地址、端口等,使得每个节点了解集群中其他节点的位置和角色。
- 负责集群的故障转移,包括节点的状态(flags)、GOSSIP 更新时间,使得每个节点能够共同感知故障,进行故障转移和数据恢复。
协议简化
在大规模的集群中,节点的数量可能非常多,节点之间的通信变得非常复杂。由于 GOSSIP 的理解难度,当集群出现问题时,排查和复现问题的难度非常高。为了更好的理解 GOSSIP 协议,就需要有合适的策略将问题简化。
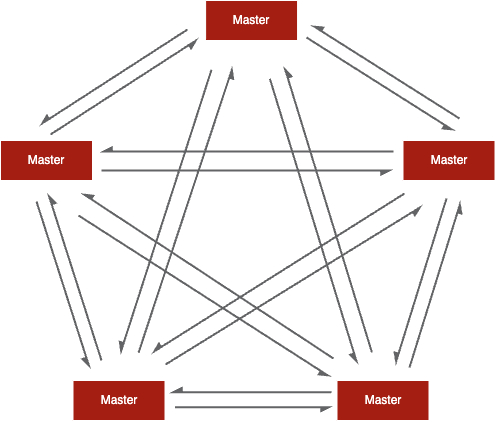
观察 Redis cluster 集群的拓扑,表现出高度的对称性。在数学中,如果一个问题具有对称性,可以利用该性质来简化计算或者找到更简洁的解决方案。利用对称性,可以对集群拓扑进行两次简化,假设集群节点数为 N:
- 第一次:将 N^N 的通信问题简化为 1^N 问题。即,如何更新 N 个节点中关于一个节点的 POV 信息(Point-of-view)
- 第二次:将 1^N 的通信问题简化为 1^1 问题。即,如何更新一个节点中关于另外一个节点的 POV 信息(Point-of-view)
最终将 GOSSIP 简化为如下拓扑,其中 Node B 是 GOSSIP 消息的发送方,Node A 是消息接收方:
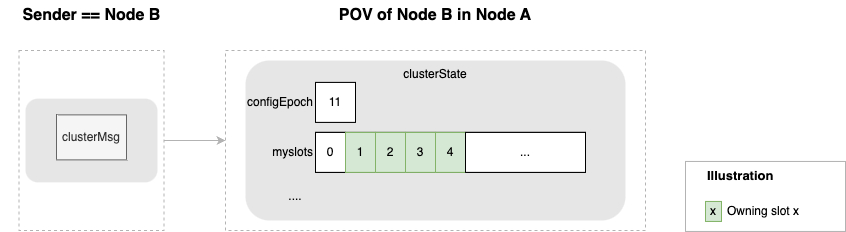
POV 更新
从 Redis 源代码易知,GOSSIP 消息主要包括消息头(clusterMsg )和消息体(clusterMsgData)两部分,结构体定义如下:
// 集群消息的结构(消息头,header)
typedef struct {
char sig[4]; /* Siganture "RCmb" (Redis Cluster message bus). */
// 消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 0. */
uint16_t notused0; /* 2 bytes not used. */
// 消息的类型
uint16_t type; /* Message type */
// 消息正文包含的节点信息数量
// 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
uint16_t count; /* Only used for some kind of messages. */
// 消息发送者的配置纪元
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
// 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
// 节点的复制偏移量
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
// 消息发送者的名字(ID)
char sender[REDIS_CLUSTER_NAMELEN]; /* Name of the sender node */
// 消息发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
// 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
// (一个 40 字节长,值全为 0 的字节数组)
char slaveof[REDIS_CLUSTER_NAMELEN];
char notused1[32]; /* 32 bytes reserved for future usage. */
// 消息发送者的端口号
uint16_t port; /* Sender TCP base port */
// 消息发送者的标识值
uint16_t flags; /* Sender node flags */
// 消息发送者所处集群的状态
unsigned char state; /* Cluster state from the POV of the sender */
// 消息标志
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
// 消息的正文(Body),包括 PING/PONG/UPDATE/MODULE/FAIL/PUBLISH 等类型
union clusterMsgData data;
} clusterMsg;POV 的是 clusterState,结构体定义如下:
// 集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
typedef struct clusterState {
// 指向当前节点的指针
clusterNode *myself; /* This node */
// 集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
// 集群当前的状态:是在线还是下线
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 集群中至少处理着一个槽的节点的数量。
int size; /* Num of master nodes with at least one slot */
// 集群节点名单(包括 myself 节点)
// 字典的键为节点的名字,字典的值为 clusterNode 结构
dict *nodes; /* Hash table of name -> clusterNode structures */
// ...
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
// ....
} clusterState;将抽象的结构体定义转换为更容易理解的图形:
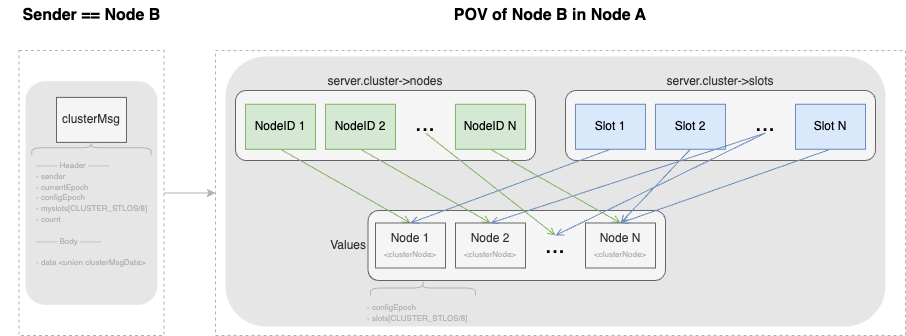
再看 Redis 对 GOSSIP 消息的处理,消息头和消息体的处理是不一样的。消息头更新消息发送者槽位分配图,而消息体更新集群拓扑及故障转移状态
集群管理缺陷
自 Redis 3.0 支持 Redis cluster 之后,集群管理的机制几乎没有太大变化。由于缺少理论的支持,社区也出现过集群管理相关的缺陷——集群槽分配不一致,(Issue #2969、Issue #3776、Issue #6339),但由于其中的复杂度,该问题并没有得到很好的解决,相关的的测试用例(21-many-slot-migration.tcl)一直没有启用。官方的临时解决方案是提供了问题检测和修复的命令行工具 redis-cli –cluster。
同样的问题,在我们的生产环境也数次出现,急需解决。根据本文上述的分析,回看槽位的更新逻辑
/* We rebind the slot to the new node claiming it if:
* 1) The slot was unassigned or the new node claims it with a
* greater configEpoch.
* 2) We are not currently importing the slot. */
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch < senderConfigEpoch)
{
// ...
if (server.cluster->slots[j] == curmaster) {
newmaster = sender;
migrated_our_slots++;
}
clusterDelSlot(j);
clusterAddSlot(sender,j);
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
}可知两点:
- 槽位总是被新 Master 认领走,已经失去槽位的旧 Master 不会对其有任何更新操作。
- 槽位总是被其归属节点的 configEpoch 看守。由于 Redis 是单线程执行,可以一定程度的将 configEpoch 理解为槽位更新的看守。
槽位的归属总是跟 configEpoch 息息相关,要理解缺陷出现的原因,就一定要去理解 configEpoch 是怎么更新的。
检索 configEpoch 更新的逻辑可知,Redis 节点仅在以下情况更新自己的 config Epoch(操作总是 currentEpoch++; configEpoch = currentEpoch):
从节点晋升为主节点
当从节点晋升为新的主节点时,它会将自己的 configEpoch 设为当前集群的 currentEpoch(当前纪元)+ 1。新的主节点就拥有了一个独立且更高的 configEpoch,以表示它接管了原主节点的角色。故障转移
当执行故障转移时,即使用CLUSTER FAILOVER命令时,从节点会请求成为新的主节点。currentEpoch 会增加1,更新为自己的 configEpoch,以表示集群配置的变更。槽位迁移
当槽位迁移完成时,IMPORTING的节点(接收槽位的节点)会在迁移完成后将 currentEpoch 增加 1 ,更新为自己的 configEpoch,以表示它接管了相应的槽位configEpoch 冲突
当节点从 GOSSIP 消息中发现其他节点的 configEpoch 与其 configEpoch 冲突(相同)时。解决冲突的方式是,此节点与具有冲突纪元的其他节点(“发送方”节点)Node ID 字典序较小的节点,将 currentEpoch 增加 1,更新为自己的 configEpoch当创建新集群时,所有节点都以相同的 configEpoch 开始(默认是0)。冲突解决函数可以让节点在启动时自动以不同的 configEpoch 结束。
总而言之,configEpoch 更新时,槽位归属并不总是更新;反之,槽位归属更新时,configEpoch 必然更新。
根据以上知识,侧重 configEpoch 与 槽位的更新重新调整 POV 更新 如下图:
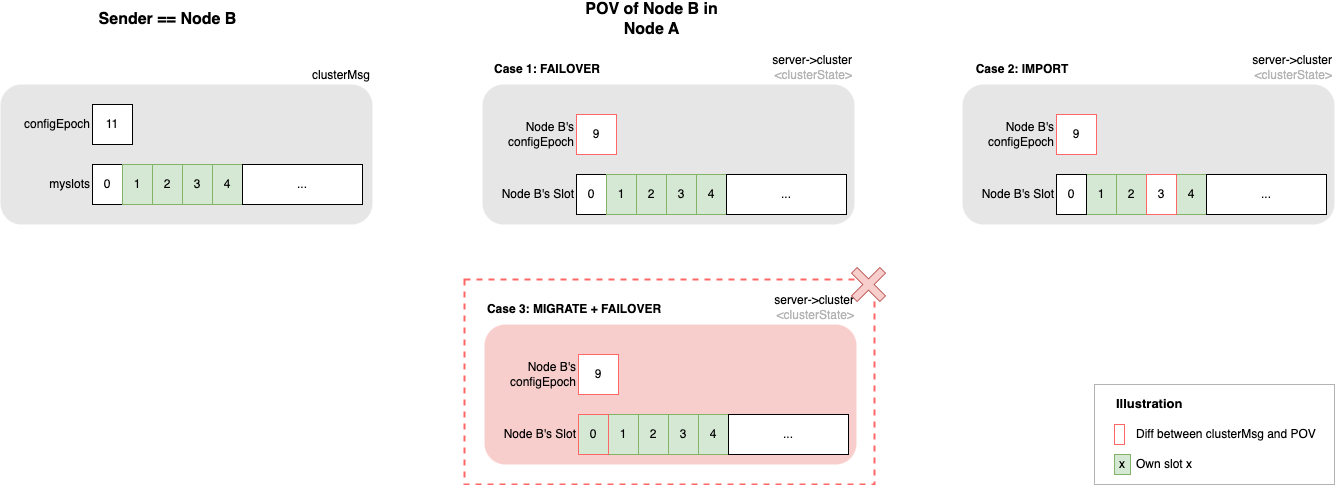
在第三种情况下,Redis cluster 的集群管理操作总是有一定概率出现无法恢复的冲突。即
在 POV 中,如果旧的 Master 有一个已经迁出的槽位尚未被新 Master 认领,单独更新 configEpoch 之后,槽位将被旧 Master 的新 configEpoch 看守起来。
旧 Master 在将此槽位迁到新 Master 之后,其 configEpoch 可能再次增加。即,旧 Master 的 configEpoch 比新 Master 的 configEpoch 更大。新 Master 就无法认领该槽位。最终造成该槽位的归属错乱。
具体示例、解释可以参考 Pull Request #12336。
总结
由于 Redis 高性能的要求,Redis 的分布式注定无法使用 Raft 等强一致的协议同步进行一致性协商。虽然 Redis cluster GOSSIP 较为复杂且缺少理论论证,仍然成为目前为止去中心化架构下的最佳选择(社区更偏爱去中心化,头部科技公司反之)。理解 Redis cluster GOSSIP 协议,是使用该架构开发者的必修课。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/07-04-2023/redis-cluster-gossip.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!