
- SRE 深入理解 Linux Page Cache
- 准备实验环境
- Arch Linux 配置
- Page Cache 关键原理
- Page Cache 和基本文件操作
- Page Cache 驱逐与回收
- 关于 mmap() 文件访问的更多信息
- Cgroup v2 和 Page Cache
- 我的程序使用了多少内存或工作集大小的故事
- 直接 IO (DIO)(NOT READY)
- 高级 Page Cache 可观察性和故障排除工具
SRE 深入理解 Linux Page Cache
在本系列文章中,我将讨论 Linux Page Cache。我相信,掌握以下的理论知识和工具对于每一位 SRE 来说都是至关重要的。这种理解不仅有助于日常的 DevOps 任务,也有助于紧急调试和救火。Page Cache 经常被忽视,更好地理解它有以下好处:
- 更精确的容量规划和容器限制计算;
- 更好地调试和调查内存和磁盘密集型应用(如数据库管理系统和文件共享存储)
- 构建内存和/或 I/O 密集型临时任务(例如:备份和恢复脚本、 rsync 一行代码等)的安全和可预测的运行时。
我将展示在处理 Page Cache 相关任务和问题时,您应该记住的实用工具,如何正确使用它们理解实际内存使用情况,以及如何使用它们揭示问题。我将尝试为您提供一些接近实际情况的使用这些工具的示例。下面是我所讨论所涉及的一些工具:vmtouch、perf、 cgtouch、strace、sar 和 page-type。
此外,正如标题所说,“深入理解”,这些实用工具的内部结构将重点展示 Page Cache 的统计、事件、系统调用和内核接口。以下是在接下来的文章中我将涉及的一些示例:
- 文件:
/proc/PID/smaps、/proc/pid/pagemap、/proc/kpageflags、/proc/kpagecgroup和sysfs文件:/sys/kernel/mm/page_idle; - 系统调用:
mincore()、mmap()、fsync()、msync()、posix_fadvise()、madvise()及其他; - 不同 open 和 advise 标志
O_SYNC、FADV_DONTNEED、POSIX_FADV_RANDOM、MADV_DONTNEED等等。
我将尝试使用 Python、Go 和少量 C 语言编写的简单(几乎全部)代码示例,尽可能详细地进行说明。
最后,任何有关现代 GNU/Linux 系统的对话都必须涉及 cgroup(在我们的例子中是 v2)和 systemd 主题。我将向您展示如何利用它们来充分发挥系统的潜力,构建可靠、可观察、可控的服务,并在值班时睡个好觉。
如果读者具有中等程度的 GNU/Linux 知识和基本的编程技能,那么他们应该能够轻松理解本文内容。
所有超过 5 行的代码示例都可以在 github 上找到:sre-page-cache-article。
准备实验环境
在开始之前,我希望与读者达成共识,以便能够执行、编译和检查任何示例或代码片段。因此,我们需要一个现代的 GNU/Linux 安装来处理代码和内核。
如果您使用的是 Windows 或 Mac OS,我建议使用 Virtual Box 安装 Vagrant 。对于 GNU/Linux 发行版,我倾向于使用 Arch Linux。Arch 是现代 GNU/Linux 系统的实际示例(顺便说一句,我使用 Arch Linux)。它支持最新的内核、systemd 和 cgroup v2。
如果您已经在使用 Linux,那么您知道该怎么做 😉。
我可以使用 docker 吗?
很遗憾,不行。我们需要一个系统,可以自由发挥、突破 cgroup 限制、使用底层工具调试程序并以 root 用户身份运行代码且不受任何限制。
下面我将展示您需要在 Arch 上安装的所有内容。
Arch Linux 配置
当您的 Arch 运行时,请更新系统并安装以下软件包:
$ pacman -Sy git, base-devel, go我们需要安装 yay (https://github.com/Jguer/yay) 以便能够从社区驱动的存储库安装软件:
$ cd ~
$ git clone https://aur.archlinux.org/yay.git
$ cd yay
$ makepkg -si从 aur 安装 vmtouch 工具:
$ yay -Sy vmtouch我们需要从内核仓库获取 page-type 工具,因此安装它的最简单方法是下载 Linux 内核版本并手动编译:
$ mkdir kernel
$ cd kernel
$ wget https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/snapshot/linux-5.14.tar.gz
$ tar -xzf linux-5.14.tar.gz
$ cd linux-5.14/tools/vm
$ make
$ sudo make install现在我们几乎准备好了。我们需要生成一个测试数据文件,它将用于我们对 Page Cache 的实验:
$ dd if=/dev/random of=/var/tmp/file1.db count=128 bs=1M最后一步是删除所有 Linux 缓存,使系统变得干净:
$ sync; echo 3 | sudo tee /proc/sys/vm/drop_cachesPage Cache 关键原理
首先我们先来问一些关于 Page Cache 的合理问题:
- Linux Page Cache 是什么?
- 它解决了什么问题?
- 为什么我们称之为 «Page» Cache?
本质上,Page Cache 是虚拟文件系统(VFS)的一部分,其主要目的(正如您所猜测的)是改善读写操作的 IO 延迟。write-back 缓存算法是 Page Cache 的核心构建块。
注意
如果你对 write-back 算法感到好奇(您应该如此),它在 维基百科 上有很好的描述,我鼓励您阅读它,或者至少查看带有流程图及其主要操作的图表。
Page Cache 中的 “Page” 表示 Linux 内核使用称为页的内存单元。跟踪和管理信息的字节甚至比特会很麻烦和困难。因此,Linux 的方法(顺便说一句,不仅仅是 Linux)是在几乎所有结构和操作中使用页(**通常长度为 4K**)。因此,Page Cache 中的最小存储单位是页,无论您要读取或写入多少数据都无关紧要。所有文件 IO 请求都与一定数量的页对齐。
上述内容引出了一个重要的事实:如果您的写入小于页大小,则内核将在您的写入完成之前读取整个页。
下图展示了 Page Cache 的基本操作。我将其分为读取和写入。
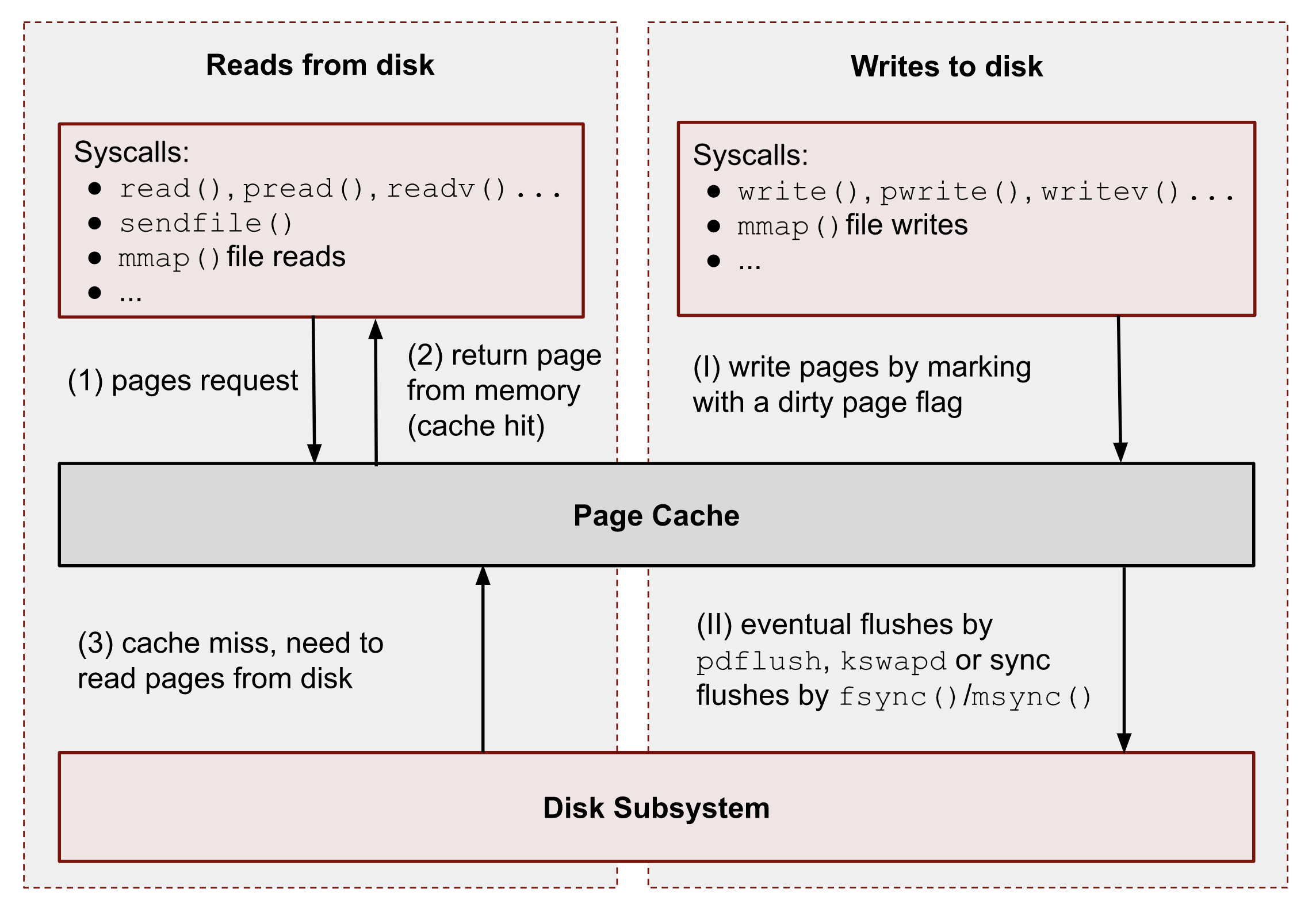
可以看到,所有数据读写都经过 Page Cache。不过 Direct IO ( DIO )有一些例外,我会在本系列的最后讨论。目前,我们先忽略它们。
注意
在接下来的章节中,我将讨论
read()、write()、mmap()以及其他系统调用。我需要指出的是,一些编程语言(例如 Python)具有同名的 file 函数。但是,这些函数并不 完全 对应到相应的系统调用。此类函数通常执行缓冲 IO。请记住这一点。
读取请求
一般来说,内核按以下方式处理读取:
- 当用户空间应用程序想要从磁盘读取数据时,它使用特殊的系统调用(例如
read()、pread()、vread()、mmap()、sendfile()等)向内核请求数据。 - Linux 内核则会检查页是否存在于 Page Cache 中,如果存在,则立即将其返回给调用者。如您所见,在这种情况下,内核没有进行任何磁盘操作。
- 如果 Page Cache 中没有这些页,内核必须从磁盘加载它们。为此,它必须在 Page Cache 中为请求的页找到一个位置。如果没有可用内存(在调用者的 cgroup 或系统中),则必须执行内存回收过程。之后,内核会安排读取磁盘 IO 操作,将目标页存储在内存中,并最终将请求的数据从 Page Cache 返回给目标进程。从此刻开始,任何未来读取文件该部分数据的请求(无论来自哪个进程或 cgroup)都将由 Page Cache 处理,而无需任何磁盘 IOP,直至这些页被驱逐。
写入请求
让我们一步步地重复写入的流程:
- 当用户空间程序想要将一些数据写入磁盘时,它也会使用一堆系统调用,例如:
write()、pwrite()、writev()、mmap()等。与读取相比,写入通常更快,因为真正的磁盘 IO 操作不会立即执行。然而,只有在系统或 cgroup 没有内存压力问题,并且有足够的可用页时,才是正确的(我们稍后会讨论驱逐过程)。所以通常内核只更新 Page Cache 中的页。它使写入流本质上是异步的。调用者不知道何时发生实际的页刷新,但它知道后续读取将返回最新数据。Page Cache 维持所有进程和 cgroup 之间的数据一致性。包含未刷新数据的此类页有一个特殊的名称:脏页。 - 如果进程的数据并不重要,它可以依靠内核及其 flush 进程,最终将数据持久保存到物理磁盘。但是,如果您开发数据库管理系统(例如,用于货币交易),则需要写入保证以保护您的记录免受突然断电的影响。对于这种情况,Linux 提供了
fsync()、fdatasync()和msync()系统调用,它们会阻塞,直到文件的所有脏页都提交到磁盘。还有open()标志:O_SYNC和O_DSYNC,您也可以使用它们来使所有文件写入操作默认持久。我稍后会展示此逻辑的一些示例。
Page Cache 和基本文件操作
现在是时候撸起袖子,开始实践一些实际的例子了。读完本章后,你将知道如何与 Page Cache 交互以及可以使用哪些工具。
本节所需的实用程序:
sync(man 1 sync) – 将所有脏页刷新到持久存储的工具;/proc/sys/vm/drop_caches(man 5 proc) – 触发 Page Cache 清除的内核procfs文件;vmtouch– 一种通过文件路径获取特定文件的 Page Cache 信息的工具。
注意
当前我们先忽略
vmtouch的工作原理。稍后我将展示如何编写一个几乎包含所有功能的替代版本。
文件读取
使用 read() 系统调用读取文件
我从简单的程序开始,该程序从测试文件 /var/tmp/file1.db 中读取前 2 个字节。
with open("/var/tmp/file1.db", "br") as f:
print(f.read(2))通常,这些类型的读取请求会被转换为 read() 系统调用。让我们使用 strace( man 1 strace ) 运行脚本以确认 f.read() 使用了 read() 系统调用:
$ strace -s0 python3 ./read_2_bytes.py输出应如下所示:
...
openat(AT_FDCWD, "./file1.db", O_RDONLY|O_CLOEXEC) = 3
...
read(3, "%B\353\276\0053\356\346Nfy2\354[&\357\300\260%D6$b?'\31\237_fXD\234"..., 4096) = 4096
...注意
尽管脚本仅请求 2 个字节,但
read()系统调用返回了 4096 个字节(一页)。这是 Python 优化和内部缓冲 IO 的一个例子。虽然这超出了本文的范围,但在某些情况下,记住这一点很重要。
现在让我们检查一下内核缓存了多少数据。为了获取此信息,我们使用 vmtouch:
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 20/32768 80K/128M 0.061%
Elapsed: 0.001188 seconds从输出可以看到,内核缓存的数据量不是 Python 请求的 2B,而是 80KiB 或 20 页。
根据设计,内核无法将小于 4KiB 或一页的内容加载到 Page Cache 中,但其他 19 页是怎么回事?这是内核预读逻辑和优先执行顺序 IO 操作而非随机 IO 操作的一个很好的例子。基本思想是预测后续读取并尽量减少磁盘寻道次数。系统调用可以控制此行为:posix_fadvise()(man 2 posix_fadvise)和 readahead()(man 2 readahead)。
注意
通常,在生产环境中,数据库管理系统和存储调整默认预读参数不会产生太大影响。如果 DBMS 不需要预读缓存的数据,则内核内存回收策略最终应将这些页从 Page Cache 中逐出。通常,顺序 IO 对内核和硬件来说并不昂贵。完全禁用预读甚至可能会导致性能下降,因为内核队列中的磁盘 IO 操作数量增加、上下文切换增多以及内核内存管理子系统识别工作集所需时间增加。我们将在本系列的后面讨论内存回收策略、内存压力和缓存写回。
现在让我们使用 posix_fadvise() 通知内核我们正在随机读取文件,因此我们不想有任何预读功能:
import os
with open("/var/tmp/file1.db", "br") as f:
fd = f.fileno()
os.posix_fadvise(fd, 0, os.fstat(fd).st_size, os.POSIX_FADV_RANDOM)
print(f.read(2))在运行脚本之前,我们需要清除所有缓存:
$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_random.py现在,如果你检查 vmtouch 输出,你会看到只有一页,正如预期的那样:
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 1/32768 4K/128M 0.00305%
Elapsed: 0.001034 seconds使用 mmap() 系统调用读取文件
为了从文件中读取数据,我们还可以使用 mmap() 系统调用 ( man 2 mmap)。mmap() 是一种“神奇”工具,可用于处理各种任务。但对于我们的测试,我们只需要其一个特性 —— 将文件映射到进程内存中,以便将文件作为扁平的数组访问。我稍后会更详细地讨论 mmap()。但目前,如果您不熟悉它,应该可以从以下示例中理解 mmap() API :
import mmap
with open("/var/tmp/file1.db", "r") as f:
with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm:
print(mm[:2])上述代码与我们刚刚使用 read() 系统调用所做的操作相同。它读取文件的前 2 个字节。
此外,出于测试目的,我们需要在执行脚本之前清除所有缓存:
$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_mmap.py检查 Page Cache 内容:
$ vmtouch /var/tmp/file1.db Files: 1. LOOK HERE
Directories: 0 ⬇
Resident Pages: 1024/32768 4M/128M 3.12%
Elapsed: 0.000627 seconds正如您所见,mmap() 执行了更为激进的预读。
让我们像之前 fadvise() 所做的那样,使用 madvise() 系统调用来改变预读。
import mmap
with open("/var/tmp/file1.db", "r") as f:
with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm:
mm.madvise(mmap.MADV_RANDOM)
print(mm[:2])运行它:
$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_mmap_random.pyPage Cache 内容:
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 1/32768 4K/128M 0.00305%
Elapsed: 0.001077 seconds从上面的输出可以看出,使用该 MADV_RANDOM 标志,我们成功地从磁盘读取了一页,并在 Page Cache 中存储了一页数据。
文件写入
现在让我们来试下写入。
使用 write() 系统调用写入
让我们继续使用我们的实验文件,并尝试更新前 2 个字节:
with open("/var/tmp/file1.db", "br+") as f:
print(f.write(b"ab"))注意
小心,不要用
w模式打开文件。它会用 2 个字节重写你的文件。我们需要r+模式。
清除所有缓存,并运行上述脚本:
sync; echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./write_2_bytes.py现在让我们检查一下 Page Cache 的内容。
$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 1/32768 4K/128M 0.00305%
Elapsed: 0.000674 seconds如您所见,我们仅写入 2B 就缓存了 1 个页。这是一个重要的观察,为了填充 Page Cache,如果您的写入大小小于页大小,则在写入之前将进行 4KiB 读取。
另外,我们可以通过读取当前 cgroup 内存统计文件来检查脏页。
获取当前终端的 cgroup:
$ cat /proc/self/cgroup
0::/user.slice/user-1000.slice/session-4.scope$ grep dirty /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat
file_dirty 4096如果看到 0,显然您很幸运,脏页已经写入磁盘,请再次运行该脚本。
使用 mmap() 系统调用写入
现在让我们使用 mmap() 重复写入:
import mmap
with open("/var/tmp/file1.db", "r+b") as f:
with mmap.mmap(f.fileno(), 0) as mm:
mm[:2] = b"ab"您可以重复上述命令,并使用 vmtouch 和 cgroupgrep 来获取脏页,您应该会得到相同的输出。唯一的例外是预读策略。默认情况下,即使对于写入请求,mmap() 也会在 Page Cache 中加载更多数据。
脏页
正如我们之前看到的,进程通过 Page Cache 写入文件会生成脏页。
Linux 提供了几种方法获取脏页数量。最早且最古老的一种方法是读取 /proc/meminfo:
$ cat /proc/meminfo | grep Dirty
Dirty: 4 kB完整的系统信息通常很难理解和使用,因为我们无法确定哪个进程和文件包含这些脏页。
这就是为什么获取脏页信息的最佳选择是使用 cgroup:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat | grep dirt
file_dirty 4096如果您的程序使用 mmap() 写入文件,您还有另一个方法可以获取进程级粒度的脏页统计信息。procfs 的 /proc/PID/smaps 文件。它包含按虚拟内存区域 (VMA) 细分的进程内存计数器。通过查找以下内容,我们可以获取脏页信息:
Private_Dirty– 此进程产生的脏数据量;Shared_Dirty– 以及其他进程写入的数量。此指标仅显示引用页的数据。这意味着进程应该访问页并将其保存在其 页表 中(稍后将详细介绍)。
$ cat /proc/578097/smaps | grep file1.db -A 12 | grep Dirty
Shared_Dirty: 0 kB
Private_Dirty: 736 kB但是如果我们想要获取某个文件的脏页统计信息该怎么办?为了回答这个问题,Linux 内核的 procfs 提供了 2 个文件:/proc/PID/pagemap 和 /proc/kpageflags。我将在本系列的后面部分展示如何使用它们编写我们自己的工具,但现在我们可以使用 Linux 内核仓库中的调试工具来获取每个文件的页信息:page-types。
$ sudo page-types -f /var/tmp/file1.db -b dirty flags page-count MB symbolic-flags long-symbolic-flags
0x0000000000000838 267 1 ___UDl_____M________________________________ uptodate,dirty,lru,mmap
0x000000000000083c 20 0 __RUDl_____M________________________________ referenced,uptodate,dirty,lru,mmap
total 287 1我根据 dirty 标志过滤出文件 /var/tmp/file1.db 的所有页 。在输出中,你可以看到文件有 287 个脏页或 1 MiB 的脏数据,这些数据最终将持久化到存储中。page-type 根据标志聚合页,因此输出中有 2 组。两者都有脏标志 D,它们之间的区别在于引用标志 R(我将在后面的 Page Cache 驱逐部分简要介绍它)。
使用 fsync()、fdatasync() 和 msync() 同步文件更改
我们已经在每次测试之前使用 sync(man 1 sync) 将所有脏页刷新到磁盘,以获得一个没有任何干扰的干净系统。但是,如果我们想编写一个数据库管理系统,并且需要确保在断电或其他硬件错误发生之前的所有写操作都将写入到磁盘,该怎么办?对于这种情况,Linux 提供了几种方法来强制内核对 Page Cache 中的文件执行同步:
fsync()– 阻塞直至目标文件及其元数据的所有脏页都被同步为止;fdatasync()– 与上述相同,但不包括元数据;msync()– 与fsync()相同,但用于内存映射文件;- 使用
O_SYNC或O_DSYNC标志打开文件,使所有文件写入默认同步,并相应地作为fsync()、fdatasync()系统调用工作。
注意
您仍然需要关注写屏障并了解底层文件系统的工作原理,因为内核调度程序可能会重新排列写操作的顺序。通常,文件追加操作是安全的,不会破坏之前写入的数据。其他类型的变异操作可能会弄乱您的文件(例如,对于 ext4,即使使用默认日志也是如此)。这就是为什么几乎所有数据库管理系统(如 MongoDB、PostgreSQL、Etcd、Dgraph 等)都具有仅追加的预写日志 (WAL)。但也有一些例外。如果您对这个主题更感兴趣,Dgraph 的这篇博客文章 是一个很好的起点。
不过也有一些例外。例如,
lmdb(及其克隆,bboltdb来自etcd)使用了一个巧妙的想法,即保留其 B+ 树的两个根并执行写时复制。
以下是文件同步的示例:
import os
with open("/var/tmp/file1.db", "br+") as f:
fd = f.fileno()
os.fsync(fd)使用 mincore() 检查 Page Cache 中的文件存在
在进一步之前,我们先弄清楚 vmtouch 如何显示目标文件 Page Cache 包含多少页。
秘密在于 mincore() 系统调用(man 2 mincore)。mincore() 代表“核心内存”。其参数是起始虚拟内存地址、地址空间长度和结果向量。 mincore() 与内存(而非文件)交互,因此可用于检查匿名内存是否已被换出。
man 2 mincore
mincore()返回一个向量,该向量指示调用进程的虚拟内存页是否驻留在内核 (RAM) 中,因此在引用时,不会导致磁盘访问 (缺页中断)。内核返回从地址 addr,长度为 length 个字节的页驻留信息。
因此,要进行复制 vmtouch,我们需要将文件映射到进程的虚拟内存中,即使我们不进行读取或写入。我们只是希望将其放在进程内存区域中(稍后在 mmap() 部分将详细介绍这一点)。
现在,我们已经准备好编写自己的简单版本 vmtouch,以便通过文件路径显示缓存页。我在这里使用 go,因为不幸的是,Python 没有一种简单的方法来调用 mincore() 系统调用:
package main
import (
"fmt"
"log"
"os"
"syscall"
"unsafe"
)
var (
pageSize = int64(syscall.Getpagesize())
mode = os.FileMode(0600)
)
func main() {
path := "/var/tmp/file1.db"
file, err := os.OpenFile(path, os.O_RDONLY|syscall.O_NOFOLLOW|syscall.O_NOATIME, mode)
if err != nil {
log.Fatal(err)
}
defer file.Close()
stat, err := os.Lstat(path)
if err != nil {
log.Fatal(err)
}
size := stat.Size()
pages := size / pageSize
mm, err := syscall.Mmap(int(file.Fd()), 0, int(size), syscall.PROT_READ, syscall.MAP_SHARED)
defer syscall.Munmap(mm)
mmPtr := uintptr(unsafe.Pointer(&mm[0]))
cached := make([]byte, pages)
sizePtr := uintptr(size)
cachedPtr := uintptr(unsafe.Pointer(&cached[0]))
ret, _, err := syscall.Syscall(syscall.SYS_MINCORE, mmPtr, sizePtr, cachedPtr)
if ret != 0 {
log.Fatal("syscall SYS_MINCORE failed: %v", err)
}
n := 0
for _, p := range cached {
// the least significant bit of each byte will be set if the corresponding page
// is currently resident in memory, and be clear otherwise.
if p%2 == 1 {
n++
}
}
fmt.Printf("Resident Pages: %d/%d %d/%d\n", n, pages, n*int(pageSize), size)
}运行它:
$ go run ./main.goResident Pages: 1024/32768 4194304/134217728并将其与 vmtouch 输出进行比较:
$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 1024/32768 4M/128M 3.12%
Elapsed: 0.000804 secondsPage Cache 驱逐与回收
到目前为止,我们已经讨论了通过读取和写入文件向 Page Cache 添加数据、检查缓存中文件的存在以及手动刷新缓存内容。但任何缓存系统最关键的部分是其驱逐策略,或者对于 Linux Page Cache,它也是内存页回收策略。与任何其他缓存一样,Linux Page Cache 会持续监视最后使用的页,并决定应删除哪些页以及应将哪些页保留在缓存中。
控制和调整 Page Cache 的主要方法是 cgroup 子系统。您可以将服务器的内存划分为几个较小的缓存(cgroup),从而控制和保护应用程序和服务。此外,cgroup 内存和 IO 控制器提供大量统计数据,这些数据对于调优软件和了解缓存的内部情况非常有用。
理论
Linux Page Cache 与 Linux 内存管理、cgroup 和虚拟文件系统 (VFS) 紧密相关。因此,为了理解驱逐的工作原理,我们需要从内存回收策略的一些基本内部原理开始。其核心结构是active 和 inactive 列表,每个 cgroup 一对:
- 第一对用于匿名内存(例如,使用
malloc()或非文件的mmap()分配); - 第二对用于 Page Cache 文件内存(所有文件操作包括
read()、write、文件的mmap()访问等)。
前者正是我们感兴趣的,linux 用于 Page Cache 驱逐过程的就是这一对,每个链表的核心都是最近最少使用算法 LRU,反过来,这 2 个链表又组成了一个 双时钟 的数据结构,一般来说 linux 应该选择最近没用过(inactive)的页,因为最近没用过的页在短时间内不会被频繁使用,这就是 LRU 算法的基本思想。active 链表和 inactive 链表的条目都采用了 FIFO(先进先出)的形式,新元素被添加到链表的头部,中间的元素逐渐向尾部移动,当需要内存回收的时候,内核总是选择 inactive 链表尾部的页进行释放,下图是该思想的简化:
!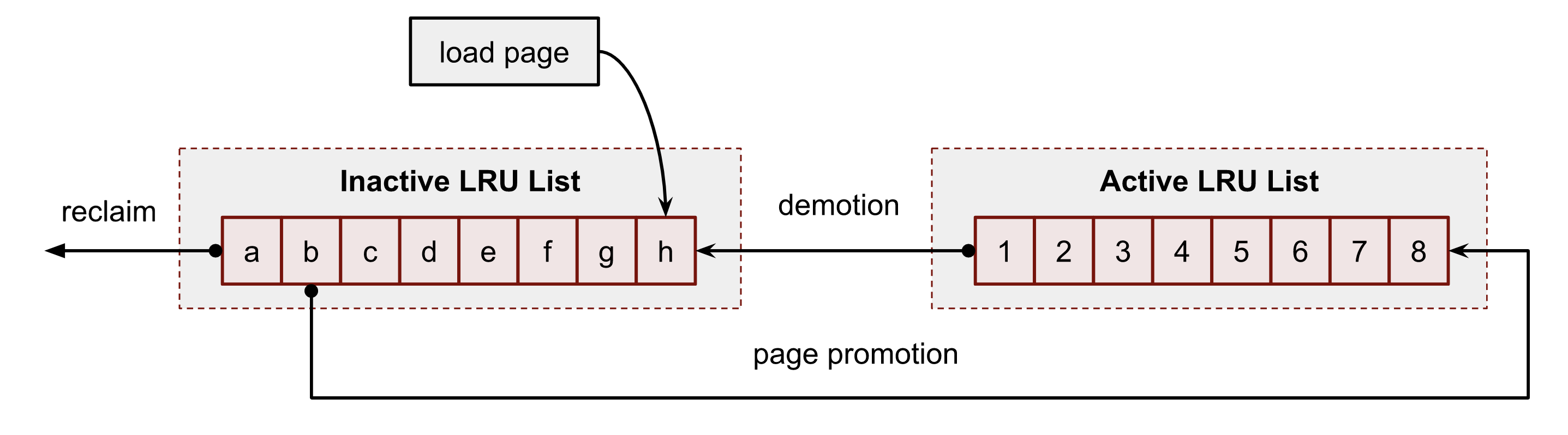
例如,系统启动时,列表的内容如下。用户进程刚刚从磁盘读取了一些数据。此操作触发内核将数据加载到缓存中。这是内核第一次访问该文件。因此,内核在进程 cgroup 的 inactive 列表的头部添加一个页 h :

一段时间后,系统又加载了 2 个额外的页:i 和 j 到 inactive 列表中,并相应地需要从列表中驱逐页 a 和 b。此操作也将所有页向 inactive LRU 列表的尾部移动,包括我们的页 h :

现在,对页 h 执行新的文件操作会将该页提升到 active LRU 列表的头部,将其置于头部。此操作还会将该页 1 移至 inactive LRU 列表的头部,并移动所有其他成员。

随着时间的推移,页 h 在 active LRU 列表中失去了其头部位置。

但一个新的文件访问到 h 在文件中的位置会将 h 移动到 active LRU 列表的头部。

上图展示了该算法的简化版本。
但值得一提的是,页提升和降级的实际过程要复杂精妙得多。
首先,如果系统有 NUMA 硬件节点 ( man 8 numastat),那么它将拥有 2 倍数量的 LRU 列表。原因是内核尝试将内存信息存储在 NUMA 节点中,以减少锁争用。
此外,Linux Page Cache 具有特殊的影子和引用标志逻辑,用于页的提升、降级和重新提升。
影子条目有助于缓解 **内存抖动问题**。当程序的工作集大小接近或大于实际内存大小(可能是 cgroup 限制或系统 RAM 限制)时,就会发生此问题。在这种情况下,读取模式可能会在随后的第二个读取请求出现之前从 inactive 列表中逐出页。完整的想法描述于 mm/workingset.c,其中包括计算 refault distance。此距离用于判断是否立即将影子条目放入 active LRU 列表。
我做的另一个简化是关于 PG_referenced 页标志。实际上,页提升和降级使用此标志作为决策算法中的额外输入参数。页提升的更正确流程:
flowchart LR
Start["Inactive LRU,
unreferenced"]
Second["Inactive LRU,
referenced"]
Third["Active LRU,
unreferenced"]
Stop["Active LRU,
referenced"]
Start --> Second
Second --> Third
Third --> Stop
使用 POSIX_FADV_DONTNEED 手动驱逐页
我已经展示了如何使用 /proc/sys/vm/drop_caches 文件清除所有页缓存条目。但如果我们出于某种原因想要清除某个文件的缓存,该怎么办?
示例
在实际情况下,从缓存中清除文件有时很有用。假设我们想测试 MongoDB 在系统重启后恢复到最佳状态的速度。您可以停止一个副本,从 Page Cache 中清除其所有文件,然后重新启动它。
vmtouch 已经可以做到这一点。它的 -e 标志命令内核从 Page Cache 中逐出所请求文件的所有页:
例如:
$ vmtouch /var/tmp/file1.db -e
Files: 1
Directories: 0
Evicted Pages: 32768 (128M)
Elapsed: 0.000704 seconds$ vmtouch /var/tmp/file1.db
Files: 1. LOOK HERE
Directories: 0 ⬇
Resident Pages: 0/32768 0/128M 0%
Elapsed: 0.000566 seconds让我们深入研究一下,弄清楚它是如何工作的。为了编写我们自己的工具,我们需要使用已见过的 posix_fadvise 系统调用和 POSIX_FADV_DONTNEED 选项。
代码:
import os
with open("/var/tmp/file1.db", "br") as f:
fd = f.fileno()
os.posix_fadvise(fd, 0, os.fstat(fd).st_size, os.POSIX_FADV_DONTNEED)为了测试,我使用 dd 将整个测试文件读入 Page Cache:
$ dd if=/var/tmp/file1.db of=/dev/null
262144+0 records in
262144+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 0.652248 s, 206 MB/s$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 32768/32768 128M/128M 100%
Elapsed: 0.002719 seconds现在,运行脚本后,我们应该在 Page Cache 中看到 0 个页:
$ python3 ./evict_full_file.py$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 0/32768 0/128M 0%
Elapsed: 0.000818 seconds让内存不可驱逐
但是,如果你想要强制内核将文件内存保留在 Page Cache, 中,无论如何,该怎么办呢?这称为使文件内存不可驱逐。
示例
有时,您必须强制内核 100% 保证您的文件不会被从内存中逐出。即使使用现代 Linux 内核和正确配置的 cgroup 限制,您也可能需要这样做,这应该会将工作数据集保留在 Page Cache 中。例如,由于共享磁盘和网络 IO 的系统上的其他进程出现问题。或者,例如,由于网络附加存储(NAS)的中断。
内核提供了一系列系统调用用于执行此操作: mlock() 、 mlock2() 和 mlockall() 。与 mincore() 类似,您必须首先映射文件。
mlock2() 是用于 Page Cache 操作的理想系统调用,因为它具有方便的标志 MLOCK_ONFAULT :
锁定当前驻留的页,并标记整个范围,当剩余的非驻留页因缺页错误而填充时,锁定新填充的页。
不要忘记考虑 limits ( man 5 limits.conf)。你可能需要增加它:
$ ulimit -l
64最后,要获取不可驱逐内存的数量,请检查对应 cgroup 的 cgroup 内存控制器的统计信息:
$ grep unevictable /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat
unevictable 0Page Cache、vm.swappiness 和现代内核
现在我们了解了基本的回收理论,包括 4 个 LRU 列表(用于匿名和文件内存)以及可驱逐/不可驱逐类型的内存,我们可以讨论重新填充系统空闲内存的来源。内核不断维护空闲页列表,以满足自身和用户空间的需求。如果此类列表低于阈值,Linux 内核将开始扫描 LRU 列表以查找要回收的页。使得内核能够保持内存处于某种平衡状态。
Page Cache 内存通常是可驱逐内存(除了一些罕见的 mlock() 例外)。因此,Page Cache 应该是内存驱逐和回收的首选和唯一选项,这看起来可能很明显。因为磁盘已经拥有了所有数据,对吧?但幸运或不幸的是,在实际生产情况下,这并不总是最好的选择。
如果系统有内存交换(现代内核应该有),内核就多了一个选择。它可以交换出匿名(非文件的)页。这似乎违反直觉,但实际情况是,有时用户空间的守护进程可以加载大量的初始化代码,但之后永远不会使用它们。例如,某些程序(尤其是静态构建的程序)的二进制文件中可能有很多功能,仅在某些边缘情况下使用几次。在所有这些情况下,将它们保存在宝贵的内存中没有多大意义。
所以,为了控制优先使用哪个 inactive LRU 列表进行扫描,内核有一个 sysctl vm.swappiness 参数。
$ sudo sysctl -a | grep swap
vm.swappiness = 60关于这个神奇的设置有很多博客文章、故事和论坛帖子。除此之外,旧版 cgroup v1 内存子系统的每个 cgroup 有自己的 swappiness 参数。所有这些都使得当前 vm.swappiness 含义的信息难以理解和更改。但让我尝试解释一些最近的更改,并为你提供最新的链接。
首先,默认 vm.swappiness 设置为 60,最小值为 0,最大值为 200:
/*
* From 0 .. 200. Higher means more swappy.
*/
int vm_swappiness = 60;值 100 意味着内核在回收方面同等考虑匿名页和 Page Cache 页。
其次,cgroup v2 内存控制器根本没有 swappiness 参数:
#ifdef CONFIG_MEMCG
static inline int mem_cgroup_swappiness(struct mem_cgroup *memcg)
{
/* Cgroup2 doesn't have per-cgroup swappiness */
if (cgroup_subsys_on_dfl(memory_cgrp_subsys))
return vm_swappiness;
/* root ? */
if (mem_cgroup_disabled() || mem_cgroup_is_root(memcg))
return vm_swappiness;
return memcg->swappiness;相反,内核开发者决定大幅改变 swappiness 逻辑。你可以通过在 mm/vmscan.c 上运行 git blame 并搜索 get_scan_count() 函数来检查它。
例如,在撰写本文时,无论 vm.swappiness 如何,只要 inactive 的 LRU Page Cache 列表中有足够的页,匿名内存都不会被触及:
/*
* If there is enough inactive page cache, we do not reclaim
* anything from the anonymous working right now.
*/
if (sc->cache_trim_mode) {
scan_balance = SCAN_FILE;
goto out;
}在关于从哪个 LRU 回收以及回收什么的决策的完整逻辑,您可以在 mm/vmscan.c 的 get_scan_count() 函数 中找到。
另外,请查看 memory.swap.high 和 memory.swap.max cgroup v2 设置。如果您想纠正 vm.swappiness 逻辑以适应您的 cgroup 和负载模式,您可以控制它们。
处理交换和 Page Cache 时,另一个值得注意的问题是换入/出过程中的 IO 负载。如果有 IO 压力,则很容易达到 IO 限制,例如,降低 Page Cache 的写回性能。
通过 /proc/pid/pagemap 理解内存回收过程
现在是时候探讨初级故障排查技术了。
有一个 /proc/PID/pagemap 文件,包含 PID 的页表信息。页表,从根本上讲,是内核在页框(存储在 RAM 中的实际物理内存页)和进程的虚拟页之间的内部映射。Linux 系统中的每个进程都有自己的虚拟内存地址空间,该空间完全独立于其他进程和物理内存地址。
/proc/PID/pagemap 相关的文件的完整的文档,包括数据格式和读取方式,可以在 内核文档文件夹 中找到。我强烈建议您在继续阅读以下部分之前先阅读它。
page-types 内核页工具
page-types 是每个内核内存黑客的瑞士军刀。其源代码随 Linux 内核源代码 tools/vm/page-types.c 一起提供。
如果你没有在第一章节安装它:
$ wget https://github.com/torvalds/linux/archive/refs/tags/v5.13.tar.gz
$ tar -xzf ./v5.13.tar.gz
$ cd v5.13/vm/tools
$ make现在让我们用它来理解,内核将我们的测试文件 /var/tmp/file1.db 的多少页放在了 Active 和 Inactive LRU 列表中:
$ sudo ./page-types --raw -Cl -f /var/tmp/file1.dbfoffset cgroup offset len flags
/var/tmp/file1.db Inode: 133367 Size: 134217728 (32768 pages)
Modify: Mon Aug 30 13:14:19 2021 (13892 seconds ago)
Access: Mon Aug 30 13:15:47 2021 (13804 seconds ago)
10689 @1749 21fa 1 ___U_lA_______________________P____f_____F_1
...
18965 @1749 24d37 1 ___U_l________________________P____f_____F_1
18966 @1749 28874 1 ___U_l________________________P____f_____F_1
18967 @1749 10273 1 ___U_l________________________P____f_____F_1
18968 @1749 1f6ad 1 ___U_l________________________P____f_____F_1
flags page-count MB symbolic-flags long-symbolic-flags
0xa000010800000028 105 0 ___U_l________________________P____f_____F_1 uptodate,lru,private,softdirty,file,mmap_exclusive
0xa00001080000002c 16 0 __RU_l________________________P____f_____F_1 referenced,uptodate,lru,private,softdirty,file,mmap_exclusive
0xa000010800000068 820 3 ___U_lA_______________________P____f_____F_1 uptodate,lru,active,private,softdirty,file,mmap_exclusive
0xa001010800000068 1 0 ___U_lA_______________________P____f_I___F_1 uptodate,lru,active,private,softdirty,readahead,file,mmap_exclusive
0xa00001080000006c 16 0 __RU_lA_______________________P____f_____F_1 referenced,uptodate,lru,active,private,softdirty,file,mmap_exclusive
total 958 3输出包含两部分:第一部分提供每页信息,第二部分汇总所有具有相同标志的页并计算摘要。为了回答 LRU 问题,我们需要从输出中获得 A 和 l 标志,正如您所猜想的那样,它们代表 “active” 和 “inactive” 列表。
如您所见,我们有:
105 + 16 = 121 pages或者121 * 4096 = 484 KiB在 inactive LRU 列表中。820 + 1 + 16 = 837 pages或者837 * 4096 = 3.2 MiB在 active LRU 列表中。
编写 Page Cache LRU 监控工具
page-types 是一款非常有用的初级调试和调查工具,但其输出格式难以阅读和汇总。我之前承诺过我们会编写自己的 vmtouch,所以现在我们正在实现它。我们的替代版本将提供更多关于页的信息。它不仅会显示 Page Cache 中有多少页,还会显示其中有多少页在 active 和 inactive LRU 列表中。
为此,我们需要两个内核文件:/proc/PID/pagemap和/proc/kpageflags。
您可以在 github repo 中找到完整的代码,但在这里,我想重点介绍几个重要时刻:
...
① err = syscall.Madvise(mm, syscall.MADV_RANDOM)
...
② ret, _, err := syscall.Syscall(syscall.SYS_MINCORE, mmPtr, sizePtr, cachedPtr)
for i, p := range cached {
③ if p%2 == 1 {
④ _ = *(*int)(unsafe.Pointer(mmPtr + uintptr(pageSize*int64(i))))
}
}
...
⑤ err = syscall.Madvise(mm, syscall.MADV_SEQUENTIAL)
...- ① – 在这里,我们需要禁用目标文件的预读逻辑,以防止我们的工具将不需要的数据加载到 Page Cache 中;
- ② – 使用
mincore()系统调用获取 Page Cache 中的页向量; - ③ – 在这里,我们检查页是否在 Page Cache 中;
- ④ – 如果 Page Cache 包含一个页,我们需要通过引用该页来更新相应进程的页表条目。我们的工具必须这样做才能使用
/proc/pid/pagemap。否则/proc/pid/pagemap文件将不包含目标文件页及其标志。 - ⑤ – 在这里,我们关闭了引用位的收集。这是由于内核回收逻辑的需要。我们的工具读取内存,因此影响内核 LRU 列表。通过使用
madvise()与MADV_SEQUENTIAL,我们通知 Linux 内核忽略我们的操作。
让我们测试一下我们的工具。我们需要 2 个终端。在第一个终端中,使用 watch( man 1 watch) 启动我们的工具,以每 100 毫秒一次,无限循环运行我们的工具:
watch -n 0.1 'sudo go run ./lru.go'在第二个终端中,我们使用 dd ( man 1 dd` ) 读取文件:
dd if=/var/tmp/file1.db of=/dev/null您应该看到的演示:

使用上述方法,您现在可以执行初级 Page Cache 调查。
关于 mmap() 文件访问的更多信息
在开始 cgroup 章节之前,我将展示如何利用内存和 IO 限制来控制 Page Cache 驱逐并提高服务的可靠性,我想更深入地研究一下 mmap() 系统调用。我们需要了解底层发生了什么,并进一步了解 mmap() 读写过程。
mmap() 概述
内存映射是 Linux 系统最有趣的功能之一。其特性之一是,软件开发者可以透明地处理文件,即使文件的大小超过系统的实际物理内存。在下图中,您可以看到进程的 虚拟内存 是什么样子。每个进程都有自己的 mmap() 映射文件的区域。
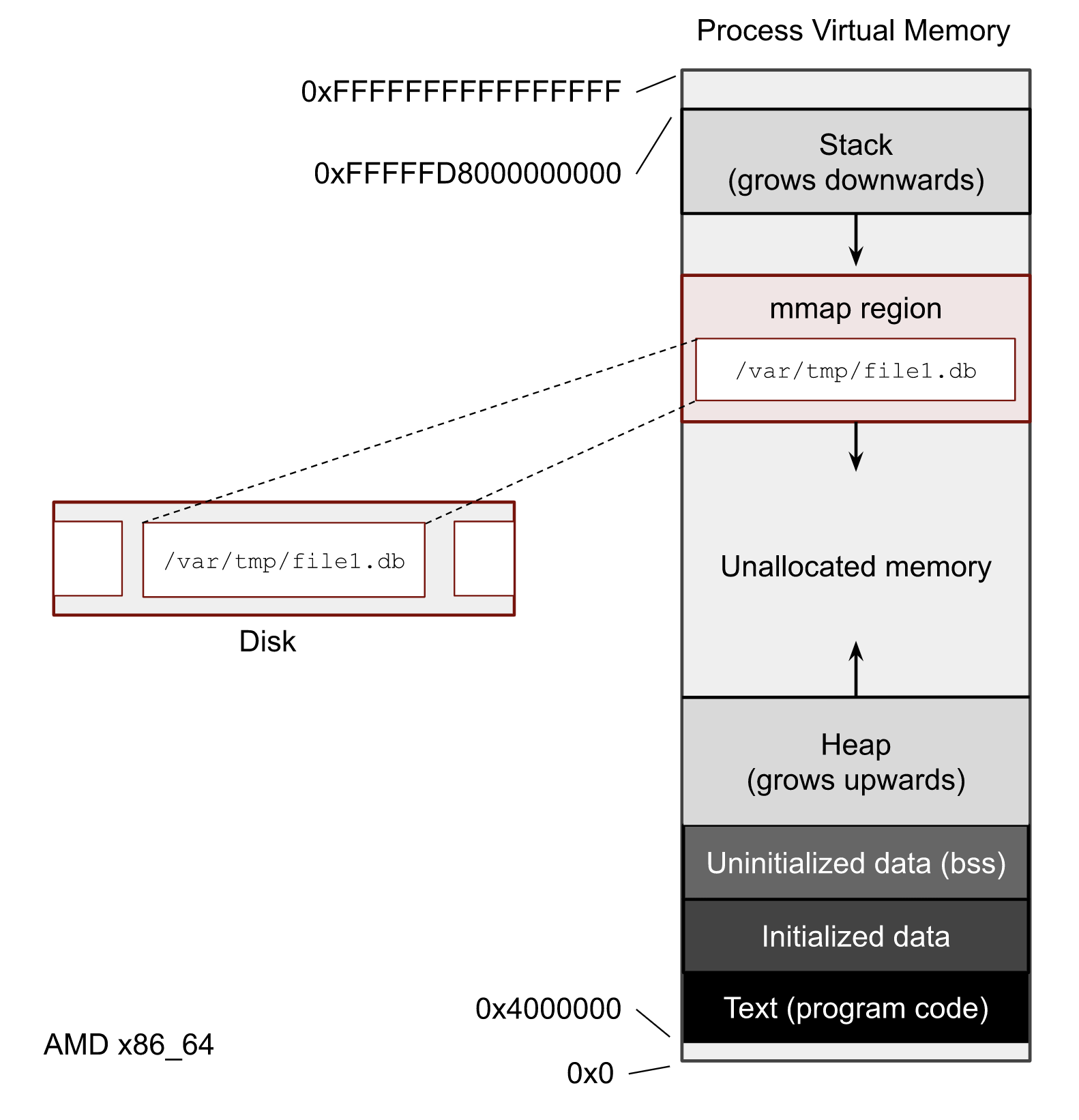
我这里不触及的的是,在你的软件中是否使用 mmap() 或文件系统调用,例如 read() 和 write()。哪种方法更好、更快或更安全超出了本文的讨论范围。但你确实需要了解如何获取 mmap() 统计数据,因为几乎所有的 Page Cache 用户空间工具都使用它。
让我们使用 mmap() 再写一个脚本。它打印进程的 PID,映射测试文件并休眠。休眠时间应该足以用该进程试验。
import mmap
import os
from time import sleep
print("pid:", os.getpid())
with open("/var/tmp/file1.db", "rb") as f:
with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm:f
sleep(10000)在一个终端窗口中运行它,然后在另一个终端窗口中, 使用脚本的 PID 运行 pmap -x PID。
pmap -x 369029 | less369029 是我的 PID。
pmap 的输出展示了进程的所有连续虚拟内存区域 (VMA 或 struct vm_area_struct)。我们可以确定 mmaped 测试文件 file1.db 的虚拟地址。在我的例子中:
Address Kbytes RSS Dirty Mode Mapping
...
00007f705cc12000 131072 0 0 r--s- file1.db我们可以看到,该文件有 0 个脏页(它仅显示此进程的脏页)。该 RSS 列等于 0,这告诉我们进程已引用了多少 KiB 内存。顺便说一句,这个 0 并不意味着 Page Cache 中没有该文件的页。这意味着我们的进程尚未访问任何页。
注意
pmap可以使用-XX显示更详细的输出。如果没有-XX,它使用/proc/pid/maps,但对于扩展模式,它显示来自/proc/pid/smaps的统计信息。更多信息可以在man 5 proc和 内核文档 filesystems/proc.rst 中找到。
因此,对于 SRE 而言,mmap() 最令人兴奋的部分是它如何在访问和写入时透明地加载数据。我将在后续章节中展示这一切。
什么是缺页中断?
在开始讨论文件工具之前,我们需要了解缺页中断的概念。一般来说,缺页中断是 CPU 与 Linux 内核及其内存子系统进行通信的机制。缺页中断是虚拟内存概念和 请求分页 的组成部分。简而言之,内核通常不会在 mmap() 或 malloc() 内存请求完成后立即分配物理内存。相反,内核会在进程的 页表结构 中创建一些记录,并将其用作内存承诺的存储。此外,页表还包含每个页的额外信息,例如内存权限和页标志(我们已经看到了其中一些:LRU 标志、脏标志等)。
从第 2 章中的示例可以看出,为了在任何位置读取映射的文件,与文件操作不同,代码不需要执行任何查找 ( man 2 lseek)。我们可以从映射区域的任何位置开始读取或写入。因此,当应用程序想要访问页时,如果目标页尚未加载到 Page Cache 中,或者 Page Cache 中的页与进程的页表之间没有连接,则可能会发生缺页中断。
有两种对我们有用的缺页中断类型:次要(minor) 和 主要。次要缺页中断基本上意味着为了满足进程的内存访问,不会有任何磁盘访问。另一方面,主要缺页中断意味着将有磁盘 IO 操作。
例如,如果我们使用 dd 加载文件一半数据到 Page Cache 中,然后从程序中使用 mmap() 访问前半部分,就会触发次要缺页中断。内核不需要访问磁盘,因为这些页已经加载到 Page Cache 中。内核只需要使用进程的页表条目引用这些已加载的页。但是,如果进程尝试在相同的映射区域中读取文件的后半部分,内核将不得不访问磁盘以加载页,系统将生成主要缺页中断。
如果您想获得有关请求分页、Linux 内核和系统内部的更多信息,请观看嵌入式 Linux Conf 的 “Linux 内存管理简介” 视频。
我们来做一个实验,写一个对文件进行不定式随机读取的脚本:
import mmap
import os
from random import randint
from time import sleep
with open("/var/tmp/file1.db", "r") as f:
fd = f.fileno()
size = os.fstat(fd).st_size
with mmap.mmap(fd, 0, prot=mmap.PROT_READ) as mm:
try:
while True:
pos = randint(0, size-4)
print(mm[pos:pos+4])
sleep(0.05)
except KeyboardInterrupt:
pass现在我们需要 3 个终端窗口。第一个:
$ sar -B 1它显示每秒的系统内存统计信息,包括缺页中断。
第二个是 perf trace:
$ sudo perf trace -F maj --no-syscalls显示主要缺页中断及其对应的文件路径。
最后,在第 3 个终端窗口中,启动上述 python 脚本:
$ python3 ./mmap_random_read.py输出应该接近以下内容:
$ sar -B 1.... LOOK HERE
⬇ ⬇
05:45:55 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
05:45:56 PM 8164.00 0.00 39.00 4.00 5.00 0.00 0.00 0.00 0.00
05:45:57 PM 2604.00 0.00 20.00 1.00 1.00 0.00 0.00 0.00 0.00
05:45:59 PM 5600.00 0.00 22.00 3.00 2.00 0.00 0.00 0.00 0.00
...查看 fault/s 和 majflt/s 字段。它们显示了我刚刚解释的内容。
通过 perf trace,我们可以获取发生主要缺页中断的文件的内部信息:
$ sudo perf trace -F maj --no-syscalls...
SCROLL ➡ LOOK HERE
⬇
5278.737 ( 0.000 ms): python3/64915 majfault [__memmove_avx_unaligned_erms+0xab] => /var/tmp/file1.db@0x2aeffb6 (d.)
5329.946 ( 0.000 ms): python3/64915 majfault [__memmove_avx_unaligned_erms+0xab] => /var/tmp/file1.db@0x539b6d9 (d.)
5383.701 ( 0.000 ms): python3/64915 majfault [__memmove_avx_unaligned_erms+0xab] => /var/tmp/file1.db@0xb3dbc7 (d.)
5434.786 ( 0.000 ms): python3/64915 majfault [__memmove_avx_unaligned_erms+0xab] => /var/tmp/file1.db@0x18f7c4f (d.)
...cgroup 也有关于每个 cgroup 的缺页中断的统计信息:
$ grep fault /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat...
pgfault 53358
pgmajfault 13
...微妙的 MADV_DONT_NEED mmap() 特性
现在我们再做一次实验。停止所有脚本并清除所有缓存:
$ sync; echo 3 | sudo tee /proc/sys/vm/drop_caches重启脚本,进行无限读取,并开始监控进程的每个内存区域的使用情况:
watch -n 0.1 "grep 'file1' /proc/$pid/smaps -A 24"现在您可以看到文件的映射区域及其信息。引用字段应该在增长。
在另一个窗口中,尝试使用 vmtouch 命令驱逐页:
vmtouch -e /var/tmp/file1.db请注意,smaps 输出中的统计数据并没有完全下降。运行 vmtouch -e 命令时,smaps 应该会显示内存使用量有所下降。问题是,发生了什么?为什么当我们通过设置 FADVISE_DONT_NEED 标志,明确要求内核驱逐文件页时,其中一些页仍然存在于 Page Cache 中?
答案有点令人困惑,但理解它非常重要。如果 Linux 内核没有内存压力问题,它为什么要从 Page Cache 中删除页?程序将来很有可能需要它们。但是,如果您作为软件开发人员确定这些页是无用的,则有 madvise() 和 MADV_DONT_NEED 标志可以使用。它通知内核可以从相应的页表中删除这些页,随后的 vmtouch -e 调用将成功地从 Page Cache 中移除文件数据。
如果出现内存压力情况,内核将开始从非活动 LRU 列表中回收内存。这意味着如果这些页适合回收,内核最终可以删除它们。
Cgroup v2 和 Page Cache
cgroup 子系统是公平分配和限制系统资源的方法。它以层次结构组织所有数据,其中叶节点依赖于其父节点并继承其设置。此外,cgroup 还提供了许多有用的资源计数器和统计数据。
控制组无处不在。即使您可能没有明确使用它们,所有现代的 GNU/Linux 发行版默认都已经启用了它们,并且已经集成到了 systemd 中。这意味着现代 Linux 系统中的每个服务都在自己的 cgroup 下运行。
概述
在本系列文章中,我们已经多次提到了 cgroup 子系统,但现在让我们更深入地了解一下整体情况。cgroup 在理解 Page Cache 使用情况方面起着至关重要的作用。它还通过提供详细的统计数据,来帮助调试问题并更好地配置软件。如前所述,LRU 列表使用 cgroup 内存限制来做出驱逐决定并确定 LRU 列表的长度。
在 cgroup v2 中,另一个重要主题是正确跟踪 Page Cache IO 写回的方式,而之前的 v1 版本无法实现这一点。v1 无法理解哪个内存 cgroup 会生成磁盘 IOPS,因此会错误地跟踪和限制磁盘操作。幸运的是,新的 v2 版本修复了这些问题。它已经提供了许多新功能来帮助 Page Cache 写回。
找出所有 cgroup 及其限制的最简单方法是访问 /sys/fs/cgroup。但您可以使用更方便的方法来获取此类信息:
systemd-cgls和systemd-top以了解 cgroupssystemd包含的内容;below,top类似 cgroups 的工具 https://github.com/facebookincubator/below
内存 cgroup 文件
现在我们从 Page Cache 的角度来回顾一下 cgroup 内存控制器中最重要的部分。
memory.current– 显示 cgroup 及其后代当前使用的总内存量。当然,它包括 Page Cache 大小。
注意
您可能很想使用这个值来设置您的 cgroup/容器内存限制,但是请等待下一章。
memory.stat– 显示了很多内存计数器,对我们来说最重要的可以通过file关键字进行过滤:
$ grep file /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat
file 19804160 ❶
file_mapped 0 ❷
file_dirty 0 ❸
file_writeback 0 ❹
inactive_file 6160384 ❺
active_file 13643776 ❺
workingset_refault_file 0 ❻
workingset_activate_file 0 ❻
workingset_restore_file 0 ❻在此处
- ❶
file– Page Cache 的大小; - ❷
file_mapped– 使用mmap()的映射文件内存大小; - ❸
file_dirty– 脏页大小; - ❹
file_writeback– 目前正在刷新多少数据; - ❺
inactive_file和active_file– LRU 列表的大小; - ❻
workingset_refault_file、workingset_activate_file和workingset_restore_file– 指标,以便更好地理解内存抖动和二次缺页中断(refault)逻辑。
memory.numa_stat– 显示上述统计数据,但针对每个 NUMA 节点。memory.min,memory.low,memory.high和memory.max– cgroup 限制。我不想重复 cgroup v2 文档,建议您先阅读它。但您需要记住的是,使用硬性限制max或min并不是您的应用程序和系统的最佳策略。您可以选择的更好方法是仅设置low和/或high限制,使其更接近您认为的应用程序工作集大小。我们将在下一节中讨论测量和预测。memory.events– 显示 cgroup 触及上述限制的次数:
memory.events
low 0
high 0
max 0
oom 0
oom_kill 0memory.pressure– 此文件包含压力阻塞信息 (PSI,Pressure Stall Information)。它通过测量由于内存不足而损失的 CPU 时间,来显示 cgroup 内存的总体健康状况。此文件是理解 cgroup 中的回收过程以及 Page Cache 的关键。让我们更详细地讨论一下 PSI。
压力阻塞信息 (PSI)
在 PSI 出现之前,很难判断系统和/或 cgroup 是否存在资源竞争;cgroup 限制是过度承诺还是配置不足。如果 cgroup 的限制可以设置得更低,那么它的阈值在哪里?PSI 功能可以缓解这些困惑,不仅让我们能够实时获取这些信息,还让我们能够设置用户空间触发器并获取通知,以最大限度地提高硬件利用率,而不会降低服务质量和带来 OOM 风险。
PSI 适用于内存、CPU 和 IO 控制器。例如,内存的输出:
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0在此处
some– 表示在 10、60 和 300 秒内,至少有一项任务在内存中阻塞了一定百分比的挂机时间。“总计”字段显示以微秒为单位的绝对值,以显示峰值;full– 含义相同,但适用于 cgroup 中的所有任务。此指标可以很好地指示问题,通常意味着资源配置不足或软件设置错误。
示例
systemd-oom守护进程,作为现代 GNU/Linux 系统的一部分,使用 PSI 比内核的 OOM 更主动地识别内存稀缺并找到要终止的目标。
我强烈建议阅读原始的 PSI 文档。
写回和 IO
cgroup v2 实现的最重要特性之一是可以跟踪、观察和限制每个 cgroup 的 Page Cache 异步写回。现在,内核写回过程可以识别要使用哪个 cgroup IO 限制来将脏页持久保存到磁盘。
但同样重要的是,它也能在另一个方面发挥作用。如果一个 cgroup 遇到内存压力,并试图通过刷新其脏页来回收一些页,它将使用自己的 IO 限制,不会损害其他 cgroup。因此,内存压力转化为磁盘 IO,如果有大量写入,最终转化为 cgroup 的磁盘压力。两个控制器都有 PSI 文件,应该用于主动管理和调整软件设置。
为了控制脏页刷新频率,Linux 内核有几个 sysctl 参数。如果你愿意,你可以让后台写回过程更积极或更消极:
$ sudo sysctl -a | grep dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
vm.dirtytime_expire_seconds = 43200上述某些方法也适用于 cgroup。内核选择并应用最先到达的整个系统或 cgroup 的项。
cgroup v2 还带来了新的 IO 控制器:io.cost 和 io.latency。它们提供了两种不同的方法来限制和保证磁盘操作。请阅读 cgroup v2 文档以获取更多详细信息和区别。但我想说,如果您的设置并不复杂,那么从侵入性较小的方法 io.latency 开始是有意义的。
与内存控制器一样,内核也提供了一堆文件来控制和观察 IO:
io.stat– 包含每个设备数据的统计文件;io.latency– 延迟目标时间(单位:微秒);io.pressure– PSI 文件;io.weight– 如果选择了io.cost的目标权重;io.cost.qos以及io.cost.model–io.costcgroup 控制器的配置文件。
内存和 IO cgroup 所有权
多个 cgroups 中的几个进程显然可以处理相同的文件。例如, cgroup1 可以打开并读取文件的前 10 KiB,稍后,另一个 cgroup2 可以向同一文件的末尾追加 2 KiB 并读取前 4 KiB。问题在于,内核将使用哪个进程的内存和 IO 限制?
内存所有权(包括 Page Cache)的逻辑是基于每个页构建的。页的所有权在首次访问(缺页中断)时确定,并且在此页被完全回收和驱逐之前,不会切换到任何其他 cgroup。所有权一词意味着这些页将用于计算 cgroup Page Cache 使用量,并将被纳入所有统计数据中。
例如,cgroup1 是前 10KiB 的所有者,而 cgroup2 – 是最后 2KiB 的所有者。无论 cgroup1 对文件做什么,甚至关闭文件,只要 cgroup2 与文件的前 4KiB 进行交互, cgroup1 就会一直保留前 4KiB(而不是全部 10KiB)的所有权。在这种情况下,内核会将页保存在 Page Cache 中,并相应地不断更新 LRU 列表。
对于 cgroup IO,所有权按 inode 计算所有权。因此,对于我们的示例,cgroup2 拥有文件的所有写回操作。在首次写回时,inode 被分配给 cgroup,但与内存所有权逻辑不同,如果内核注意到另一个 cgroup 生成的脏页更多,IO 所有权可能会迁移到另一个 cgroup。
为了排除内存所有权问题,我们应该使用一对 procfs 文件:/proc/pid/pagemap 和 /proc/kpagecgroup。page-type 工具支持显示每页 cgroup 信息,但很难将其用于文件目录并获得格式良好的输出。这就是为什么我编写了自己的 cgtouch 工具来排查 cgroup 内存所有权问题的原因。
$ sudo go run ./main.go /var/tmp/ -v/var/tmp/file1.db
cgroup inode percent pages path
- 85.9% 28161 not charged
1781 14.1% 4608 /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope
--
/var/tmp/ubuntu-21.04-live-server-amd64.iso
cgroup inode percent pages pat
- 0.0% 0 not charged
2453 100.0% 38032 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u10.service
--
Files: 2
Directories: 7
Resident Pages: 42640/70801 166.6M/276.6M 60.2%
cgroup inode percent pages path
- 39.8% 28161 not charged
1781 6.5% 4608 /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope
2453 53.7% 38032 /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u10.service安全的临时任务
假设我们需要运行 wget 命令或通过调用配置管理系统(例如 saltstack)手动安装某些软件包。这两项任务的磁盘 I/O 都可能非常繁重。为了安全地运行它们并且不与任何生产负载交互,我们不应该在根 cgroup 或当前终端 cgroup 中运行它们,因为它们通常没有任何限制。所以我们需要一个具有一些限制的新 cgroup。手动为您的任务创建一个 cgroup,并手动配置每个临时任务会非常繁琐和麻烦。但幸运的是,我们不必这样做,所以所有现代 GNU/Linux 发行版都内置了 systemd,带有开箱即用的 cgroup v2。systemd-run 以及 systemd 许多其他很酷的功能使我们的生活更轻松,并节省了大量时间。
例如,wget 任务可以按以下方式运行:
systemd-run --user -P -t -G --wait -p MemoryMax=12M wget http://ubuntu.ipacct.com/releases/21.04/ubuntu-21.04-live-server-amd64.iso
Running as unit: run-u2.service ⬅ LOOK HERE
Press ^] three times within 1s to disconnect TTY.
--2021-09-11 19:53:33-- http://ubuntu.ipacct.com/releases/21.04/ubuntu-21.04-live-server-amd64.iso
Resolving ubuntu.ipacct.com (ubuntu.ipacct.com)... 195.85.215.252, 2a01:9e40::252
Connecting to ubuntu.ipacct.com (ubuntu.ipacct.com)|195.85.215.252|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1174243328 (1.1G) [application/octet-stream]
Saving to: ‘ubuntu-21.04-live-server-amd64.iso.5’
...run-u2.service 是我的全新 cgroup,具有内存限制。我可以获取其指标:
$ find /sys/fs/cgroup/ -name run-u2.service
/sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u2.service$ cat /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u2.service/memory.pressure
some avg10=0.00 avg60=0.00 avg300=0.00 total=70234
full avg10=0.00 avg60=0.00 avg300=0.00 total=69717$ grep file /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u2.service/memory.stat
file 11100160
file_mapped 0
file_dirty 77824
file_writeback 0
file_thp 0
inactive_file 5455872
active_file 5644288
workingset_refault_file 982
workingset_activate_file 0
workingset_restore_file 0如您所见,我们有近 12MiB 的文件内存和一些二次缺页中断(refault)。
要了解 systemd 和 cgroup 的所有功能,请阅读其 资源控制文档。
我的程序使用了多少内存或工作集大小的故事
目前,在容器、自动扩展和按需云的世界中,理解服务在正常常规情况和接近软件极限的压力下的资源需求至关重要。但每当有人谈到内存使用量时,几乎立即就不清楚要测量什么和如何测量。RAM 是一种宝贵且通常昂贵的硬件类型。在某些情况下,它的延迟甚至比磁盘延迟更重要。因此,Linux 内核会尽可能地优化内存利用率,例如通过在进程之间共享相同的页。此外,Linux 内核还具有 Page Cache,以便通过将磁盘数据的子集存储在内存中来提高存储 IO 速度。Page Cache 不仅本质上执行隐式内存共享(通常会让用户感到困惑),而且还在后台主动异步地与存储一起工作。因此,Page Cache 为内存使用量估算表带来了更多的复杂性。
在本章中,我将演示一些方法,您可以使用它们来确定内存(以及 Page Cache)限制的初始值,并从一个不错的起点开始您的旅程。
一切都关乎谁重要,或独一无二的集合大小的故事
我听到过的关于内存和 Linux 的两个最常见的问题是:
- 我所有的可用内存在哪里?
- 您/我/他们的应用程序/服务/数据库使用了多少内存?
第一个问题的答案应该对读者显而易见(悄悄说 “Page Cache”)。但第二个问题要棘手得多。通常,人们认为 top 或 ps 输出的 RSS 列是评估内存利用率的良好起点。虽然这种说法在某些情况下可能是正确的,但它通常会导致对 Page Cache 重要性,及其对服务性能和可靠性的影响的误解。
让我们以著名的 top( man 1 top)工具 为例,来调查它的内存消耗。它是用 C 语言编写,只做一件事,就是在循环中打印进程的状态。top 并不大量使用磁盘,因此也不使用 Page Cache。它不涉及网络。它的唯一目的是从 procfs 中读取数据,并以友好的格式显示给用户。所以它的工作集应该很容易理解,不是吗?
让我们在新的 cgroup 中启动 top 过程:
$ systemd-run --user -P -t -G --wait top在另一个终端,让我们开始学习。从 ps 开始:
$ ps axu | grep top
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
vagrant 611963 0.1 0.2 10836 4132 pts/4 Ss+ 11:55 0:00 /usr/bin/top
... ⬆
LOOK HERE如上所示,根据 ps 输出, top 进程使用了大约 4MiB 的内存。
现在让我们从 procfs 及其 /proc/pid/smaps_rollup文件 获取更多详细信息,基本上是 /proc/pid/smaps 中所有内存区域的总和。对于我的 PID:
$ cat /proc/628011/smaps_rollup
55df25e91000-7ffdef5f7000 ---p 00000000 00:00 0 [rollup]
Rss: 3956 kB ⓵
Pss: 1180 kB ⓶
Pss_Anon: 668 kB
Pss_File: 512 kB
Pss_Shmem: 0 kB
Shared_Clean: 3048 kB ⓷
Shared_Dirty: 0 kB ⓸
Private_Clean: 240 kB
Private_Dirty: 668 kB
Referenced: 3956 kB ⓹
Anonymous: 668 kB ⓺
...我们主要关心以下几行:
- ⓵
RSS– 一个众所周知的指标,正如我们在ps输出中看到的内容。 - ⓶
PSS– 代表进程的比例共享内存。这是一个人工内存指标,它应该能给你一些关于内存共享的洞察:
进程的“比例集大小”(
PSS) 是其在内存中的页数,其中每个页除以共享它的进程数。因此,如果一个进程有 1000 个页完全属于自己,还有 1000 个页与另一个进程共享,则其 PSS 为 1500。
- ⓷
Shared_Clean– 是一个有趣的指标。正如我们之前假设的,我们的进程理论上不应该使用任何 Page Cache,但事实证明它确实使用了 Page Cache。正如您所见,它是内存使用的主要部分。如果您打开每区域的文件/proc/pid/smaps,您可以找出原因是共享库。它们都是用mmap()打开的,并且驻留在 Page Cache 中。 - ⓸
Shared_Dirty– 如果我们的进程使用mmap()写入文件,则此行将显示未保存的脏 Page Cache 的数量。 - ⓹
Referenced- 表示进程迄今为止标记为引用或访问的内存量。我们在本mmap()部分提到过这个指标。如果没有内存压力,它应该接近 RSS。 - ⓺
Anonymous– 显示不属于任何文件的内存量。
从上面我们可以看出,虽然 top 输出的 RSS 为 4MiB,但其大部分 RSS 都隐藏在 Page Cache 中。理论上,如果这些页在一段时间内处于非活动状态,内核可以将它们从内存中驱逐。
我们也来看看 cgroup 统计数据:
$ cat /proc/628011/cgroup
0::/user.slice/user-1000.slice/user@1000.service/app.slice/run-u2.service$ cat /sys/fs/cgroup/user.slice/user-1000.slice/user@1000.service/app.slice/run-u2.service/memory.stat
anon 770048
file 0
...
file_mapped 0
file_dirty 0
file_writeback 0
...
inactive_anon 765952
active_anon 4096
inactive_file 0
active_file 0
...我们在 cgroup 中看不到任何文件内存。这是 cgroup 内存记账特性的另一个很好的例子。另一个 cgroup 已经计算了这些库。
为了完成并复查,让我们使用 page-type 工具:
$ sudo ./page-types --pid 628011 --raw
flags page-count MB symbolic-flags long-symbolic-flags
0x2000010100000800 1 0 ___________M_______________r_______f_____F__ mmap,reserved,softdirty,file
0xa000010800000868 39 0 ___U_lA____M__________________P____f_____F_1 uptodate,lru,active,mmap,private,softdirty,file,mmap_exclusive
0xa00001080000086c 21 0 __RU_lA____M__________________P____f_____F_1 referenced,uptodate,lru,active,mmap,private,softdirty,file,mmap_exclusive
0x200001080000086c 830 3 __RU_lA____M__________________P____f_____F__ referenced,uptodate,lru,active,mmap,private,softdirty,file
0x8000010000005828 187 0 ___U_l_____Ma_b____________________f_______1 uptodate,lru,mmap,anonymous,swapbacked,softdirty,mmap_exclusive
0x800001000000586c 1 0 __RU_lA____Ma_b____________________f_______1 referenced,uptodate,lru,active,mmap,anonymous,swapbacked,softdirty,mmap_exclusive
total 1079 4我们可以看到,top 进程的内存包含文件 mmap() 区域,因此使用了 Page Cache。
现在让我们为我们的 top 进程获取一个唯一的内存集大小。进程的唯一内存集大小或 USS 是仅此目标进程使用的内存量。此内存可以是共享的,但如果没有其他进程使用它,它仍然归入 USS 中。
我们可以使用 page-types 的 -N 标志和一些 shell 魔法来计算进程的 USS:
$ sudo ../vm/page-types --pid 628011 --raw -M -l -N | awk '{print $2}' | grep -E '^1$' | wc -l
248上述表示该 top 进程的唯一集合大小(USS)是 248 pages 或者 992 KiB。
或者我们可以利用我们对 /proc/pid/pagemap、/proc/kpagecount 和 /proc/pid/maps 的知识,编写自己的工具来获取唯一集合大小。此类工具的完整代码可以在 github repo 中找到。
如果我们运行它,我们应该得到与 page-type 相同的输出:
$ sudo go run ./main.go 628011
248既然我们了解了估计内存使用量有多么困难,以及 Page Cache 在这种计算中的重要性,我们准备向前迈出一大步,开始考虑具有更多活跃磁盘活动的软件。
空闲页和工作集大小
读到这里读者可能会对另一个内核文件感到好奇:/sys/kernel/mm/page_idle。
您可以使用它来估计进程的工作集大小。主要思想是使用特殊空闲标志标记一些页,并在一段时间后检查有关工作数据集大小的差异假设。
您可以在 Brendan Gregg 的 仓库 中找到很棒的参考工具。
让我们为 top 进程运行它:
$ sudo ./wss-v1 628011 60
Watching PID 628011 page references during 60.00 seconds...
Est(s) Ref(MB)
60.117 2.00上述意味着,在 4MiB 的 RSS 数据中,该进程在 60 秒间隔内仅使用 2MiB。
欲了解更多信息,您还可以阅读这篇 LWN 文章。
该方法的缺点如下:
- 对于占用大量内存的进程来说,它可能会很慢;
- 所有测量都在用户空间进行,因此会消耗额外的 CPU;
- 它完全脱离了您的进程可能产生的写回压力。
虽然这可能成为您的容器的合理起始限制,我将向您展示一种更好的方法,使用 cgroup 统计信息和压力阻塞信息 (PSI) 。
使用压力阻塞信息(PSI)计算内存限制
正如系列中所见,我强调将所有服务分别运行在自己的 cgroups 中,并且精心配置限制是非常重要的。这通常会带来更好的服务性能以及更均匀、更正确地系统资源使用。
但仍然不清楚从哪里开始。选择哪个值?使用 memory.current 值好吗?还是使用唯一集合大小?还是使用空闲页标志来估计工作集大小?虽然所有这些方法在某些情况下可能都很有用,但我建议在一般情况下使用以下的 PSI 方法。
在继续使用 PSI 之前,关于 memory.current 还有一点需要注意。如果 cgroup 没有内存限制,并且系统有大量可用内存供进程使用,则 memory.current 只会显示应用程序到目前为止使用的所有内存(包括 Page Cache)。它可能包含应用程序运行时不需要的大量垃圾。例如,日志记录、不需要的库等。使用 memory.current 值作为内存限制会浪费系统资源,并且不会对您进行容量规划有帮助。
解决这个难题的现代方法是,使用 PSI 来了解 cgroup 如何对新的内存分配和 Page Cache 驱逐的反应。senapi 是一个简单的自动脚本,用于收集和解析 PSI 信息并调整 memory.high:
让我们用我的测试 MongoDB 安装进行实验。我有 2.6GiB 的数据:
$ sudo du -hs /var/lib/mongodb/
2.4G /var/lib/mongodb/现在我需要生成一些随机读取查询。在 mongosh 中,我可以运行一个无限循环,并每 500 毫秒读取一条随机记录:
while (true) {
printjson(db.collection.aggregate([{ $sample: { size: 1 } }]));
sleep(500);
}在第二个终端窗口中,我使用带有 mongodb 服务 cgroup 启动 senpai
sudo python senpai.py /sys/fs/cgroup/system.slice/mongodb.service
2021-09-05 16:39:25 Configuration:
2021-09-05 16:39:25 cgpath = /sys/fs/cgroup/system.slice/mongodb.service
2021-09-05 16:39:25 min_size = 104857600
2021-09-05 16:39:25 max_size = 107374182400
2021-09-05 16:39:25 interval = 6
2021-09-05 16:39:25 pressure = 10000
2021-09-05 16:39:25 max_probe = 0.01
2021-09-05 16:39:25 max_backoff = 1.0
2021-09-05 16:39:25 coeff_probe = 10
2021-09-05 16:39:25 coeff_backoff = 20
2021-09-05 16:39:26 Resetting limit to memory.current.
...
2021-09-05 16:38:15 limit=503.90M pressure=0.030000 time_to_probe= 1 total=1999415 delta=601 integral=3366
2021-09-05 16:38:16 limit=503.90M pressure=0.030000 time_to_probe= 0 total=1999498 delta=83 integral=3449
2021-09-05 16:38:16 adjust: -0.000840646891233154
2021-09-05 16:38:17 limit=503.48M pressure=0.020000 time_to_probe= 5 total=2000010 delta=512 integral=512
2021-09-05 16:38:18 limit=503.48M pressure=0.020000 time_to_probe= 4 total=2001688 delta=1678 integral=2190
2021-09-05 16:38:19 limit=503.48M pressure=0.020000 time_to_probe= 3 total=2004119 delta=2431 integral=4621
2021-09-05 16:38:20 limit=503.48M pressure=0.020000 time_to_probe= 2 total=2006238 delta=2119 integral=6740
2021-09-05 16:38:21 limit=503.48M pressure=0.010000 time_to_probe= 1 total=2006238 delta=0 integral=6740
2021-09-05 16:38:22 limit=503.48M pressure=0.010000 time_to_probe= 0 total=2006405 delta=167 integral=6907
2021-09-05 16:38:22 adjust: -0.00020961438729431614如您所见,根据 PSI,503.48M 内存足以支持我的读取工作负载,不会出现任何问题。
这显然是 PSI 功能的预览,对于真正的生产服务,您可能也应该考虑一下 io.pressure。
… 那么写回又如何呢?
说实话,这个问题比较难回答。在我写这篇文章的时候,我还不知道有什么好的工具可以评估和预测写回和 IO 的使用情况。不过,经验法则是先从中学习 io.latency,然后在需要的时候尝试使用 io.cost。
还有一个有趣的新项目 resctl-demo,它可以帮助正确识别限制。
直接 IO (DIO)(NOT READY)
像往常一样,任何规则总有例外。Page Cache 也不例外。因此,让我们来谈谈文件读写,这些操作可以忽略 Page Cache 内容。
为什么它很好
某些应用程序需要对存储子系统进行底层访问,Linux 内核通过提供 O_DIRECT 文件打开标志提供了这样的功能。此 IO 称为直接 IO 或 DIO。使用此标志打开文件,程序完全绕过内核 Page Cache,直接与 VFS 和底层文件系统通信。
优点是:
- 降低 CPU 占用率,从而获得更高的吞吐量;
- Linux Async IO(
man 7 aio) 仅适用于 DIO(io_submit); - 零拷贝避免 Page Cache 和用户空间缓冲区之间的双缓冲;
- 更好地控制写回。
- …
为什么它不好,需要 io_uring 替代方案
- 需要将读写与块大小对齐;
- 并非所有文件系统在实现 DIO 时都相同;
- 没有 Linux AIO 的 DIO 很慢而且根本没用;
- 非跨平台;
- 不能同时对文件进行 DIO 和缓冲 IO。
- …
如果没有 AIO,DIO 通常就没有意义,但是 AIO 有很多 糟糕的设计决策:
所以我认为这极其丑陋。
AIO 是一种糟糕的临时设计,其主要借口是“其他不太有天赋的人做出了这种设计,而我们为了兼容性而实现它,因为数据库人员——他们实际上很少有品味——实际上会使用它”。
但 AIO 总是非常非常丑陋。
Linus Torvalds
注意!使用 DIO 仍然需要在文件上运行
fsync()!
让我们用 iouring-go 库编写 golang 一个 例子:
TODO高级 Page Cache 可观察性和故障排除工具
让我们介绍一些高级工具,可以用于执行底层内核跟踪和调试。
eBPF 工具
首先,我们可以使用 eBPF 工具。当你想获取一些内部内核信息时,bcc 和 bpftrace 是你的好帮手。
让我们来看看它自带的一些工具。
写回监控
$ sudo bpftrace ./writeback.bt
Attaching 4 probes...
Tracing writeback... Hit Ctrl-C to end.
TIME DEVICE PAGES REASON ms
15:01:48 btrfs-1 7355 periodic 0.003
15:01:49 btrfs-1 7355 periodic 0.003
15:01:51 btrfs-1 7355 periodic 0.006
15:01:54 btrfs-1 7355 periodic 0.005
15:01:54 btrfs-1 7355 periodic 0.004
15:01:56 btrfs-1 7355 periodic 0.005Page Cache Top
19:49:52 Buffers MB: 0 / Cached MB: 610 / Sort: HITS / Order: descending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
66229 vagrant vmtouch 44745 44032 0 50.4% 49.6%
66229 vagrant bash 205 0 0 100.0% 0.0%
66227 root cachetop 17 0 0 100.0% 0.0%
222 dbus dbus-daemon 16 0 0 100.0% 0.0%
317 vagrant tmux: server 4 0 0 100.0% 0.0%缓存统计信息
[vagrant@archlinux tools]$ sudo ./cachestat
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
10 0 0 100.00% 0 610
4 0 0 100.00% 0 610
4 0 0 100.00% 0 610
21 0 0 100.00% 0 610
624 0 0 100.00% 0 438
2 0 0 100.00% 0 438
4 0 0 100.00% 0 438
0 0 0 0.00% 0 438
19 0 0 100.00% 0 438
0 428 0 0.00% 0 546
28144 16384 0 63.21% 0 610
0 0 0 0.00% 0 610
0 0 0 0.00% 0 610
17 0 0 100.00% 0 610
0 0 0 0.00% 0 610bpftrace 和 kfunc 跟踪
除此之外,eBPF 和 bpftrace 最近又增加了一个很棒的新功能,名为 kfunc。因此,使用它,您可以在没有安装内核调试信息的情况下跟踪一些内核函数。
它仍然接近于实验性功能,但它看起来确实很有前景。
Perf 工具
但是如果你想要更深入地了解,我可以为你提供一些东西。perf 允许你几乎在任何内核函数中设置动态跟踪内核探测器。唯一的问题是需要安装内核调试信息。不幸的是,并非所有发行版都提供它,有时你可能需要添加一些额外的标志手动重新编译内核。
但是当你获得调试信息时,你可以进行非常疯狂的调查。例如,如果我们想跟踪主要缺页中断,我们可以找到负责的内核函数(https://elixir.bootlin.com/linux/latest/source 及其帮助搜索)并安装一个探针:
perf probe -f "do_read_fault vma->vm_file->f_inode->i_ino"其中,do_read_fault 是我们的内核函数,vma->vm_file->f_inode->i_ino 是发生主要缺页中断的文件的 inode 编号。
现在您可以开始记录事件:
perf record -e probe:do_read_fault -ag -- sleep 10perf script10 秒后,我们可以用 bash 魔法来 grep 出 inode :
perf script | grep i_ino | cut -d ' ' -f 1,8| sed 's#i_ino=##g' | sort | uniq -c | sort -rn原文: Linux Page Cache mini book
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/12-11-2024/linux-page-cache-minibook-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!