
什么是火焰图?
2011 年,时任 Netflix 高级性能工程师的 Brendan Gregg 面临一个棘手问题:尽管 perf 能采集到海量性能数据,但使用 perf report 显示调用树摘要时,数千行堆栈信息让人如同“大海捞针”,难以发现关联路径和 CPU 热点。在 Roch Bourbonnais 的 CallStackAnalyzer 和 Jan Boerhout 的 vftrace 启发下,火焰图诞生了
火焰图(Flame Graph)是一种可视化的性能分析工具,其核心目标是将复杂的性能采样数据转化为一目了然的图形。通过横向宽度表示资源消耗(如 CPU 占用时间),纵向层级表示函数调用关系,形似跳动的火焰,让开发者能够快速锁定性能瓶颈的“火源”。
经典火焰图原理
通常意义上的 On-CPU 火焰图是指 On-CPU 火焰图用来定位代码 On-CPU 的执行热点
1. 数据采集
- 采样机制: 以固定频率(如每秒 99 次)中断程序,记录当前的函数调用链(Stack Trace)
2. 数据处理
- 聚合统计:合并相同调用链的采样点,计算每个函数在调用链中的出现频率
- 归一化处理:将采样次数转换为百分比,消除采样时长对宽度的影响
3. 可视化规则
- 方框:每个框代表函数栈中的一个函数(一个“栈帧”)。方框的宽度显示该函数 on-CPU 的总时间,或部分祖先函数 on-CPU 的总时间(基于样本计数)。带有宽方框的函数每次执行可能比带有窄方框的函数消耗更多 CPU,或者可能只是调用频率更高。
- Y 轴: 表示栈深度(栈上的帧数)。顶部的方框显示当前处于 CPU 运行状态的函数。函数下方的第一个函数是其父函数,下方的所有函数均为其祖先函数
- X 轴: 涵盖整体样本。从左到右按字母顺序排列,以最大化合并帧(从左到右并非显示时间的流逝)
Off-CPU 火焰图原理
经典的 CPU 火焰图虽然能精准定位代码在 CPU 上的执行热点,但现实中线程可能因 I/O 阻塞、锁竞争、内存争用等原因离开 CPU,这些等待时间占比较高但传统火焰图无法捕捉;就催生了 Off-CPU 火焰图,目标是处于阻塞状态和 Off-CPU 状态的线程,如下图中蓝色部分所示。Off-CPU 分析是对 CPU 分析的补充,因此可以了解 100% 的线程时间。
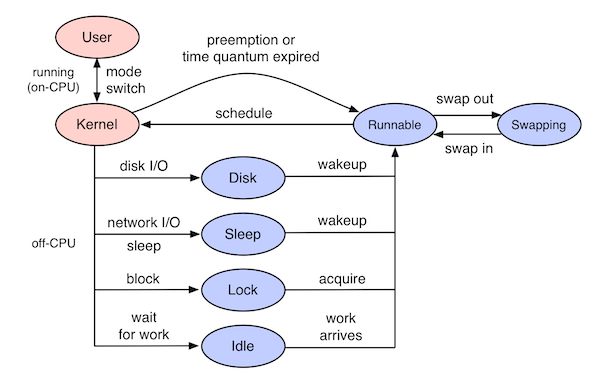
1. 数据收集: 通过内核级工具(如 offcputime from BCC)记录线程的 上下文切换(context switch) 事件
- Off-CPU 开始:当线程被调度出 CPU(如调用
schedule()函数)时,记录时间戳和调用栈 - On-CPU 恢复:当线程重新被调度到 CPU 时,计算阻塞时长(
恢复时间戳 - 离开时间戳) - 阻塞类型: 结合阻塞事件的内核态信息(如系统调用、锁类型、I/O 类型)
- 调用栈: 用户态 + 内核态
2. 数据聚合: 按调用栈路径合并相同栈的阻塞时间,生成 [调用栈] -> 总耗时 的映射表
- 时间累加:将同一调用栈路径的所有阻塞时间累加,形成时间占比。
3. 可视化规则: 将调用栈按层级展开,生成火焰图
- 宽度:表示阻塞时间的占比
- 颜色:可区分阻塞类型(如红色为 I/O,蓝色为锁)
- 层级:显示从顶层函数到底层系统调用的完整路径
注意:
数据收集开销
- 调度程序事件可能非常频繁——在极端情况下,每秒可能会有数百万个事件——由于事件发生频率高,数据开销可能会累积起来变得非常可观,比仅在 CPU 数量上进行 CPU 采样的开销要高出几个数量级。
- 如果对新的调度跟踪器一无所知,可以先收集十分之一秒(0.1 秒),然后逐步增加跟踪时间,同时密切关注其对系统 CPU 利用率、应用程序请求率和应用程序延迟的影响。同时考虑上下文切换的速率(例如,通过 vmstat 中的“cs”列测量),并且在速率更高的服务器上要更加小心
阻塞唤醒
- 许多 Off-CPU 堆栈显示了阻塞路径,但没有显示阻塞的完整原因。该原因和代码路径位于另一个线程,即调用唤醒阻塞线程的线程
- 另外的工具 wakeuptime 和 offwaketime,可以测量唤醒堆栈并将它们与 off-CPU 堆栈关联起来
Broken stack
火焰图的数据采集步骤,一般会使用 perf Linux 分析器。该工具的使用工作流详见:slides、youtube,不重复。着重记录:如何处理函数栈不完整。由于省略帧指针 (Omitting frame pointer) 通常是编译器优化的默认选项,就导致 perf_events 中的函数栈不完整。有三种方法可以解决这个问题:使用 dwarf 数据展开堆栈,使用最后分支记录 (LBR,如果可用,处理器特性),或者返回帧指针。
Frame Pointers 帧指针
应用程序使用编译器优化 (-O2) 会省略了帧指针,可以使用 -fno-omit-frame-pointer 重新编译。内核堆栈跟踪不完整,需要调整内核配置选项 CONFIG_FRAME_POINTER=y。该方法不适合已经有问题的线上环境,调整选项的成本过高。
Dwarf
从 3.9 内核开始,perf_events 支持一种解决用户级堆栈中缺少帧指针的解决方法:libunwind,它使用 dwarf 函数。可以使用“–call-graph dwarf”(或“-g dwarf”)启用此功能
perf record -F 99 -p 59715 --call-graph dwarf -- sleep 120LBR
必须拥有“最后分支记录”访问权限才能使用此功能。该权限在大多数云环境中均处于禁用状态,您会收到以下错误:
# perf record -F 99 -a --call-graph lbr
Error:
PMU Hardware doesn't support sampling/overflow-interrupts.另外,LBR 的堆栈深度通常有限(8、16 或 32 帧),因此不适合用于深层堆栈或火焰图生成,因为火焰图需要走到公共根节点进行合并。
容器环境
容器化部署的场景下,如果容器是 alphine,而宿主机是 ubuntu。首先在宿主机上对容器内的进程执行 perf record,然后在宿主机执行 perf script,也会因为容器与宿主机的 用户态符号环境不兼容导致函数栈异常。可以进入容器环境,然后指定宿主机的内核符号表路径 (应该有更好的处理方案?)
perf script --header -i perf.data --kallsyms /proc/kallsyms --no-inline > perf.perf火焰图的局限
On-CPU/Off-CPU 火焰图覆盖了 100% 的线程时间,那是否把它们结合起来就能解决所有的性能问题呢? 答案是否定的。在分析 吞吐量(Throughput) 和 延迟(Latency) 时,既要关注指标的平均值,还要关注到 P99、P99.9 分位值、Max 值。 On-CPU/Off-CPU 火焰图就会失效,主要原因在于:
1. 采样机制的天然局限
- 基于定时采样的工具(如
perf)更易捕获高频执行的代码路径。 - 低频冷路径可能从未被采样命中(如采样间隔为 10ms,而冷路径 2 秒仅触发一次)。
2. 时间聚合的视角陷阱
- On-CPU/Off-CPU 的宽度反映总时间,而非单次执行成本,无法区分以下两种场景:
- 高频低耗(热路径):
执行次数 × 单次时间 = 总时间 - 低频高耗(冷路径):
执行次数 × 单次时间 = 总时间
- 高频低耗(热路径):
- 冷路径因总时间占比低,在火焰图中会被压缩成“细线”而忽视
Flamescope 使用 亚秒级偏移热力图 和 火焰图 来分析周期性活动、 方差和扰动,在一定程度上解决了这些问题,但对于一些极端 Case 仍然力有未逮。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/04-13-2025/flamegraph-summary.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!