
背景
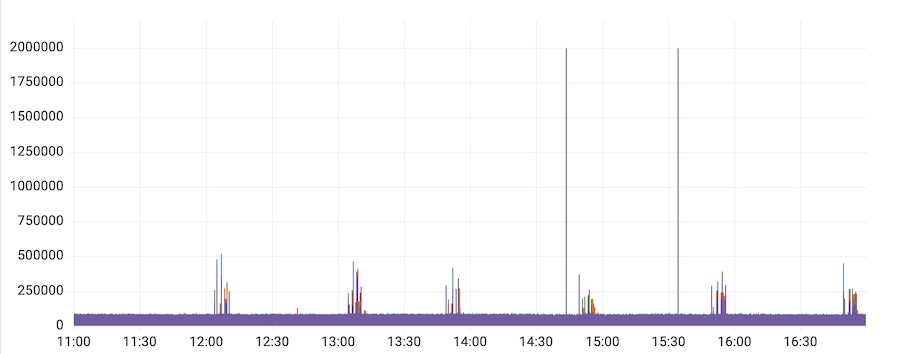
该问题发生于去年的十二月份,业务发现部分线上集群再次出现延迟毛刺。只是现象与上次不同:
- 延迟出现的时间点不固定,逐渐发生变化
- 延迟较为规律的每小时出现一次
- 持续时间大概有差不多十分钟,不是一瞬间
问题定位
相比八月份出现类似问题的状态,整个系统的监控系统和定位能力更加完备,包含主调和被调耗时以及耗时百分位。
缩小范围
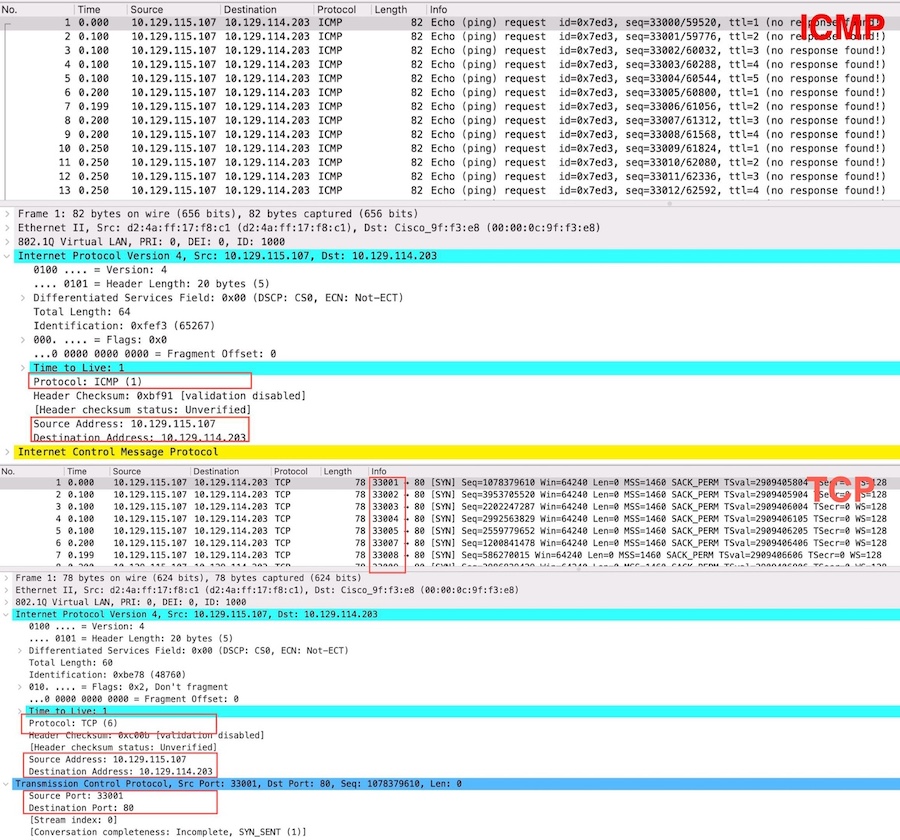
通过 Redis Proxy 主调 Redis 的监控看板,可以观察到明显的耗时毛刺。
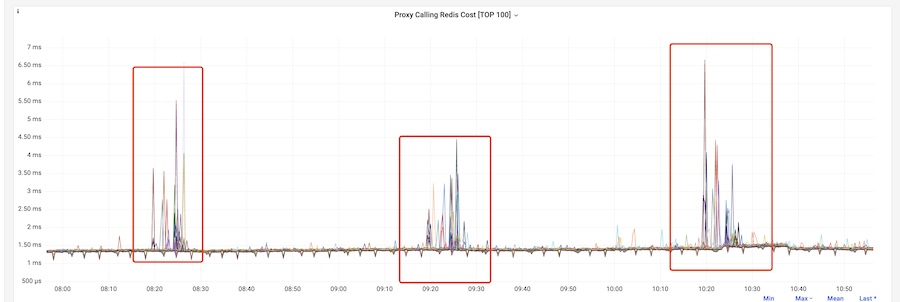
然后,使用 ebpf 抓取 Redis 执行耗时也并未发现慢速命令,说明并非是业务使用命令导致的。
基于以上手段以及整体架构很容易将问题范围缩小到:Redis Proxy 调用 Redis 链路。
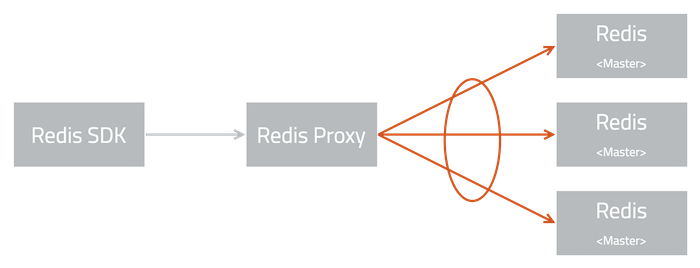
接下来,我们将注意力转向了网络层面。
调用链路分析
首先,在问题出现的时间点,使用 MTR 检查网络丢包和延迟,一切正常。
再次,检查问题集群的上层交换机,一切正常。
最后,检查某个主机的监控时,终于发现了与延迟匹配的指标。
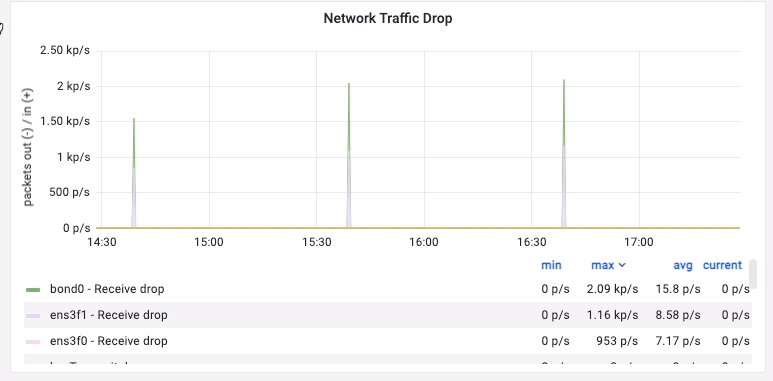
经网络团队检查,看到机器上 rx missed_errors 比较高
$> ethtool -S eno2 |grep rx |grep error
IX_errors: 0
Ix_over_errors: 0
Ix_crc_errors: o
IX_ frame_errors: 0
IX_fifo_errors: 0
rx missed_errors: 2071867
IX_length_errors: 0
Ix_long_length_errors: 0
rx_short_length_errors: 0找了一台机器调高 ring buffer 大小为 4096。
$> ethtool -G <nic> rx 4096 # 增加 RX 队列的大小到 4096$> ethtool -g eno2 # 查询网卡队列长度
Ring parameters for eno2:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 512持续观察一天,问题不再复现。
网络团队的同事判断是业务层有周期性阻塞性的任务,导致软中断线程收包阻塞,rx drop 是因为软中断线程收包慢导致的。 使用字节跳动团队的 trace-irqoff,可以观测到以下输出
$> cat /proc/trace_irqoff/trace_latency
softirq: cpu: 2
COMMAND: ethtool PID: 95974 LATENCY: 29+ms trace_irqoff_record+0x2a6/0x330 [trace_irqoff] trace_irqoff.
_hrtimer_handler+0xcb/0xd4 [trace_irqoff]
__hrtimer_run_queues+0xca/0x1d0
hrtimer_interrupt+0x109/0x230 __sysvec_apic_timer_
_interrupt+0x61/0xd0
sysvec_apic_timer_interrupt+0x77/0x90
asm_sysvec_apic_timer_interrupt+0x12/0x20
ixgbe_read_reg+0x33/0xf0 [ixgbe]
ixgbe_lower_i2c_clk+0x4a/0x60 [ixgbe]
ixgbe_clock_in_i2c_byte+0xc0/0x120 [ixgbe]
ixgbe_read_i2c_byte_generic_int+0x20f/0x270 [ixgbe]
ixgbe_read_12c_byte_generic+0x1b/0x20 [ixgbel
ixgbe_read_i2c_eeprom_generic+0x21/0x30 [ixgbe]
ixgbe_get_module_eeprom+0x6f/0x100 [ixgbe]
ethtool_get_module_eeprom_call+0x5b/0x70
ethtool_get_any_eeprom+0xf9/0x1b0
dev_ethtool+0x1e9a/0x2980
dev_ioctl+0x145/0x530
sock_do_ioctl+0xa9/0x100
sock_ioctl+0xef/0x310
__x64_sys_ioctl+0x91/0xc0
do_syscall_64+0x5c/Oxc0
entry_SYSCALL_64_after_hwframe+0x44/Oxae
COMMAND: ksoftirqd/2 PID: 28 LATENCY: 227ms trace_irqoff_record+0x2a6/0x330 [trace_irqoff]
trace_irqoff_timer_handler+0x48/0x80 [trace_irqoff]
call_timer_fn+0x2e/0x110
run_timer_softirq+0x36e/0x480
__do_softirq+0xf0/0x33e
run_ksoftirqd+0x2b/0x40
smpboot_thread_fn+0xba/0x150
kthread+0x12a/0x150
ret_from_fork+0x22/0x30看到下面的进程 ksoftirqd/2 的栈,延迟时间是 227ms。ksoftirqd 进程是 kernel 中处理 softirq 的进程。因此这段栈是没有意义的,因为元凶已经错过了。所以此时,可以借鉴上面的栈信息,看到当 softirq 被延迟 29+ms 的时候,当前 CPU 正在执行的进程是 ethtool。ethtool 的 lantency 提示信息 29+ms 是阈值信息,并非实际 latency(所以后面添加一个 ‘+’ 字符,表示 latency 大于 29ms)。实际的 latency 是 ksoftirqd/2 显示的 227ms。原来是有人用 ethtool 读 eeprom 导致网卡阻塞丢包了。
团队同事使用以下命令,扫描机器上可执行程序:
$> find /usr/bin /usr/sbin /usr/local/bin /usr/local/sbin -type f -executable ! -path "/usr/sbin/ethtool" -print0 | xargs -0 strings -f | grep -w 'ethtool'
/usr/bin/node-exporter: ethtool
/usr/bin/udevadm: ../src/shared/ethtool-util.c
...因为是问题是持续定时发生的,识别过滤出两个常驻后台的可执行程序,逐一确认。
经相关同事确认,故障出现的前一两天确实灰度了光模块监控,会调用 ethtool -m 读取光模块的信息。程序灰度时间与问题出现的时间一致,程序回滚之后问题恢复。原来是程序是被逐个机器遍历的远程调用完成数据抓取,并且根据上次完成的时间偏移固定的时间来启动下次数据抓取。也就解释了为何会出现背景中描述的毛刺特征。
问题复盘
MTR 能探测主机丢包么?要回答这个问题首先要了解以下几个问题:
- MTR 是怎么探测是否有丢包的?
- TCP 主机上是怎么负载均衡的 ?
- 主机有哪些环节可能导致丢包?
MTR 原理
在使用 ICMP(TCP) 探测时,mtr 发送 ICMP ECHO(TCP SYN) 数据包到目标主机(的指定端口)。目标主机收到数据包后,会响应 ICMP ECHO REPLY(TCP SYN-ACK)数据包。mtr 记录下从发送数据包到接收到响应数据包之间的延迟,并将这些信息显示给用户。
当网络数据包到达网卡时,硬件中断会被触发,然后系统会调度 ksoftirqd 线程来处理数据包,进行协议栈的进一步处理。并在软中断上下文中完成 ICMP(TCP)协议响应(以及 TCP 的连接状态管理,如 SYN、ACK、FIN 等)。以 ICMP 为例,相关内核逻辑如下
// https://elixir.bootlin.com/linux/v4.6/source/net/ipv4/icmp.c#L893
/*
* Handle ICMP_ECHO ("ping") requests.
*
* RFC 1122: 3.2.2.6 MUST have an echo server that answers ICMP echo
* requests.
* RFC 1122: 3.2.2.6 Data received in the ICMP_ECHO request MUST be
* included in the reply.
* RFC 1812: 4.3.3.6 SHOULD have a config option for silently ignoring
* echo requests, MUST have default=NOT.
* See also WRT handling of options once they are done and working.
*/
static bool icmp_echo(struct sk_buff *skb)
{
struct net *net;
net = dev_net(skb_dst(skb)->dev);
if (!net->ipv4.sysctl_icmp_echo_ignore_all) {
struct icmp_bxm icmp_param;
icmp_param.data.icmph = *icmp_hdr(skb);
icmp_param.data.icmph.type = ICMP_ECHOREPLY;
icmp_param.skb = skb;
icmp_param.offset = 0;
icmp_param.data_len = skb->len;
icmp_param.head_len = sizeof(struct icmphdr);
icmp_reply(&icmp_param, skb);
}
/* should there be an ICMP stat for ignored echos? */
return true;
}与 TCP 协议相关的定时器(例如 TCP 重传定时器),是通过
kworker内核线程处理的。定时器触发时,内核线程会进行重传、ACK 处理等操作。
RSS 硬件多队列
多数主机网卡都支持 RSS(Receive Packet Steering)功能,网卡会有多个接受队列,旨在根据接收到的数据包计算哈希值,并将包分配到不同的接收队列,以便多个 CPU 核心并行处理数据包。查看网卡队列数量:
$ ethtool -l eno1
Channel parameters for eno1:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 128
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 48 # 启用的网卡队列数RSS 的负载均衡通常基于数据包的 五元组,包括:
- 源 IP 地址
- 目的 IP 地址
- 源端口(TCP/UDP)
- 目的端口(TCP/UDP)
- 协议类型(TCP/UDP/ICMP)
当使用 MTR 进行探测时,可以指定所使用的协议类型 ICMP 或 TCP。RSS 在处理 ICMP 包时,只会基于三元组:
- 源 IP 地址
- 目的 IP 地址
- 协议类型(ICMP)
当 RSS 处理 ICMP 包时,网卡会基于这三元组计算一个哈希值,随后将该哈希值与网卡的队列数量进行取模运算,决定数据包被分配到哪个硬件队列,所以具有相同源 IP、目的 IP 和协议的 ICMP 流量通常会被固定分配到某个特定的队列。
对比来看,TCP 协议会不断更改请求包的来源端口,进而可以覆盖所有队列。
对于低概率的丢包事件,除了考虑负载均衡,还要考虑探测的频率。 MTR 默认的发包频率是 1 秒,root 用户可以通过 -i 参数来指定 0 到 1 之间的值以提高探测频率,并且保障一定的时长来检测丢包。抑或使用 hping3 直接向终点 IP 发送数据包,而不对中间的路由跳数进行探测。
$> hping3 -S 10.129.114.203 -p 80
HPING 10.129.114.203 (bond0.1000 10.129.114.203): S set, 40 headers + 0 data bytes
len=46 ip=10.129.114.203 ttl=61 DF id=0 sport=80 flags=RA seq=0 win=0 rtt=3.7 ms
len=46 ip=10.129.114.203 ttl=61 DF id=0 sport=80 flags=RA seq=1 win=0 rtt=3.7 ms
len=46 ip=10.129.114.203 ttl=61 DF id=0 sport=80 flags=RA seq=2 win=0 rtt=7.6 msRPS 软件多队列
对于不支持多队列或队列数显著少于 CPU 数的主机(如:基于 82598 网络连接的 Intel 网卡仅支持 16 个队列),需要开启软件实现的多队列,即 RPS。RPS 类似的基于数据包的五元组(源 IP、目的 IP、源端口、目的端口、协议类型),将接收队列的网络数据包分发到多个 CPU 核的 backlog 队列。再由各个 CPU 上软中断线程将数据包交给 L2、L3、L4 协议解析,最终到达 socket 缓存区。如此旧避免网络处理集中在单个(部分) CPU 核上,从而造成瓶颈或资源不平衡。整体流程参考:译|Monitoring and Tuning the Linux Networking Stack - Receiving Data
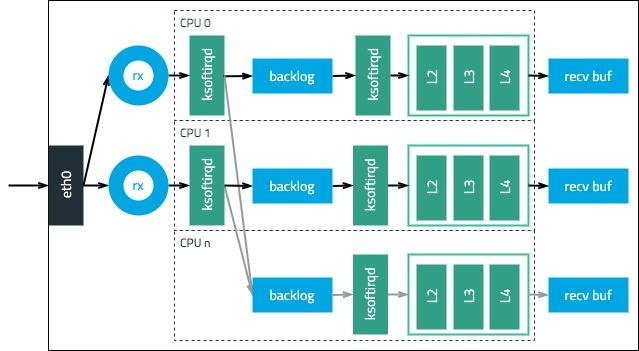
主机丢包环节
对于本次故障的场景,由于没有连接异常断开,所有长连接均处于 ESTABLISHED 状态。那么,连接建立阶段的丢包的因素就可以不用考虑。因此就可以重点考虑最关键的三个队列是否溢出:RX 队列、backlog 队列、Socket 接收缓存区。
由于 TCP 是面向连接的协议,有流控机制,当接收缓冲区满时,发送方会停止发送数据,直到缓冲区有空闲空间为止,因此 TCP 丢包的概率较小。其他两个队列的丢包情况,则可以通过 ethtool 查看,即上文提及的排查命令。
推而广之,怎么覆盖上层协议栈的丢包呢?使用 netstat -s 命令,可以查看网络协议栈各层的详细统计信息,包括 IP、TCP、UDP、ICMP。如果具体到定位丢包原因,则需要其他可观测性的工具。
考虑到数据包处理路径的复杂度,Linux 内核从 5.15 版本开始引入了 skb_drop_reason 以追溯根因。它通过为丢包原因提供一组标准化的枚举值 skb_drop_reason enum ,让开发者能够更清楚地看到丢包的具体原因,并可以通过工具在 skb:kfree_skb 跟踪点上添加探测器来监控包丢弃情况。
$> perf record -e skb:kfree_skb curl https://localhost
curl: (7) Failed to connect to localhost port 443: Connection refused
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.040 MB perf.data (4 samples) ]
$> perf script
curl 163406 [036] 7681948.959483: skb:kfree_skb: skbaddr=0xffff8a68e752cc00 protocol=0 location=0xffffffff8efced8e reason: NOT_SPECIFIED
curl 163406 [036] 7681948.959574: skb:kfree_skb: skbaddr=0xffff8a68ed61d2e0 protocol=34525 location=0xffffffff8f0177e9 reason: NOT_SPECIFI>
curl 163406 [036] 7681948.959728: skb:kfree_skb: skbaddr=0xffff8a68ed61d2e0 protocol=2048 location=0xffffffff8ef64c2b reason: NO_SOCKET
curl 163406 [036] 7681948.959779: skb:kfree_skb: skbaddr=0xffff8a68ed61d2e0 protocol=2048 location=0xffffffff8ef64c2b reason: NO_SOCKET腾讯、字节等厂在此基础上进行了更加友好的封装:nettrace、netcap
总结
针对该类偶现问题,由于短期波动对整体趋势影响较小,抓取现场获取瞬时值(即时值)的难度颇高。相反,累计值能够保存历史记录,并且随着时间的推移,累计值的数据量可能变得非常大,更适合分析。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/09-17-2024/redis-latency-irqoff.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!